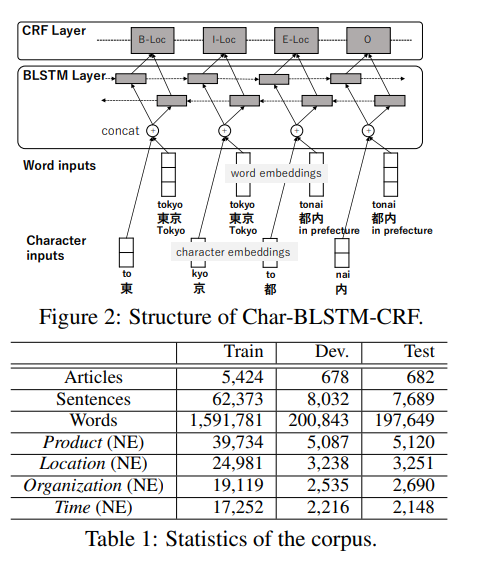
This is a brief summary of paper for me to study and arrange for Character-based Bidirectional LSTM-CRF with words and characters for Japanese Named Entity Recognition (Misawa et al., SCLeM 2017) I read and studied.
This paper is a research ralted to Japanese NER task applying, back then, the cutting-edge model to Japanese.
Most of neural network focused on English, So they verified neural network worked well on Japanese comparing to the conventional method of Japanese NER task.
Also while the CNN layer help performance of NER taks achieve hier performance becuase CNN can capture sub-information of a word which is capitalization, suffixes, and prefixes.
But They said the CNN has a problem in extracting sub-information in Japanese.
The reason is Japanese words tend to be shorter than English and Japanese character has no capitalization.
And They Japanese has boundary conflict problem when a part of a word compose an entity. So they finally argue the chacater-based than word-based model.
They propose character-based model to predict a tag for a character with word embeddign as follows: