This is a brief summary of paper for me to study and arrange for Exploiting Similarities among Languages for Machine Translation (Mikolov et al., arXiv 2013) I read and studied.
The following Figure can be easily seen that these concepts have similar geometric arrangements.
The reason is that as all common languages share concepts that are grounded in the real world (such as that cat is an animal smaller than a dog), there is often a strong similarity between the vector spaces.
In other words, both languages (English and Spanish) has the similarity of geometric arrangments in vector spaces.
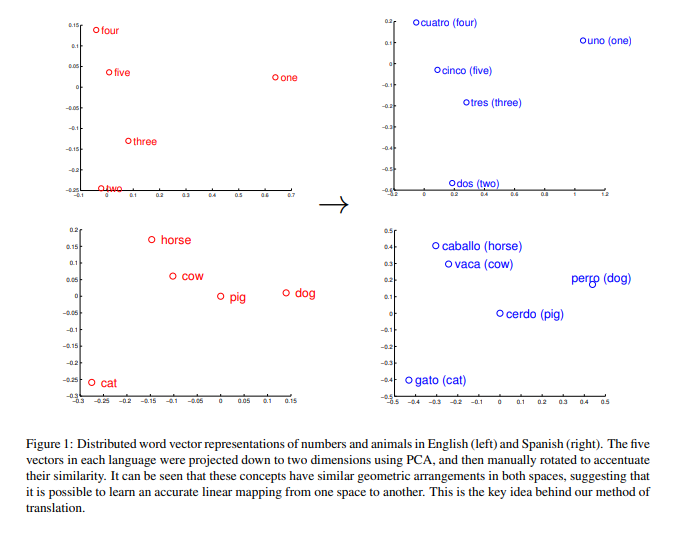
As you can see figure above, The similarity of geometric arrangments in vector spaces is the key reason why our method, which is linearly projecting from source language to target language, works well.
As they visualized the word vectors using PCA, they said that the vector representations of similar words in different languages were related by a linear transformation. For instance, Figure 1 above shows that the word vectors for English numbers one to five and the corresponding Spanish words uno to cinco have similar geometric arrangements. The relationship between vector spaces that represent these two languages can thus possibly be captured by linear mapping (namely, a rotation and scaling).
So they argued if they know the translation of one and four from English to Spanish, they can learn the transformation matrix that can help us to translate even the other numbers to Spanish.
At the test time, They translated any word that has been seen in the monolingual corpora by projecting its vector representation from the source language space to the target language space. Once they obtain the vector in the target language space, they output the most similar word vector as the translation.
For information of Word2vec
They said that the key point when using word2vec like CBOW and Skip-gram like this:
In practice, Skip-gram gives better word representations when the monolingual data is small. CBOW however is faster and more suitable for larger datasets.
The paper: Exploiting Similarities among Languages for Machine Translation (Mikolov et al., arXiv 2013)
Reference
- Paper
- How to use html for alert