This is a brief summary of paper for me to study and organize it, Linguistic Knowledge and Transferability of Contextual Representations (Liu et al., NAACL 2019) I read and studied.
This paper investigated the linguistic knowledge and transferability on contextual representation (e.g. ELMo, BERT) as follows:
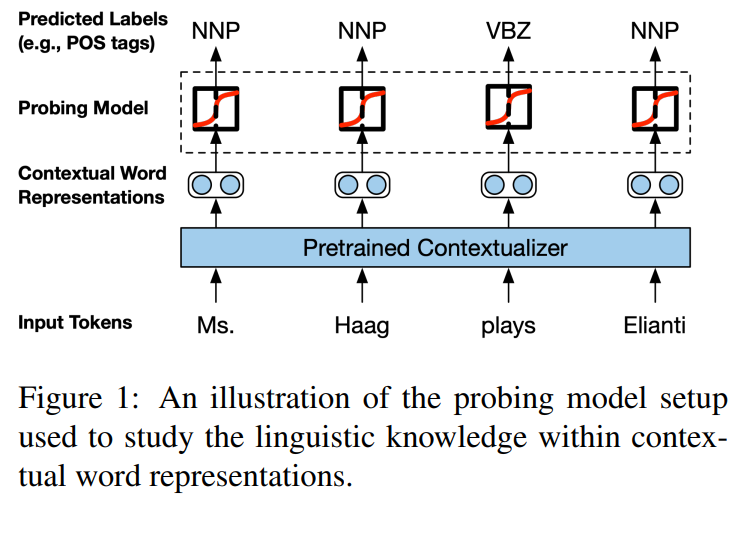
They said their analysis reveals interesting insights:
- Linear models trained on top of frozen CWRs are competitive with state-of-the-art taskspecific models in many cases, but fail on tasks requiring fine-grained linguistic knowledge. In these cases, we show that tasktrained contextual features greatly help with encoding the requisite knowledge.
- The first layer output of long short-term memory (LSTM) recurrent neural networks is consistently the most transferable, whereas it is the middle layers for transformers.
- Higher layers in LSTMs are more taskspecific (and thus less general), while the transformer layers do not exhibit this same monotonic increase in task-specificity
- Language model pretraining yields representations that are more transferable in general than eleven other candidate pretraining tasks, though pretraining on related tasks yields the strongest results for individual end tasks.
In summary, unlike Transformer, bidirectional LSTM language model yeilds the presentations that are more transferable in general that othe candidate tasks (i.e. supervied tasks)
Aslo, LSTM-based ELMo indicate the transferability and linguistic knowledge in lower layers but Transformer is in middel layer.
Unlike transformer, LSTM-based ELMo indicate the task-specific information in higher layer than lower layer.
The paper: Linguistic Knowledge and Transferability of Contextual Representations (Liu et al., NAACL 2019)
Reference
- Paper
- How to use html for alert
- For your information