This is a brief summary of paper for me to study and organize it, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data (Conneau et al., EMNLP 2017) I read and studied.
This paper propose the method to encode a sentence in a vector training on NLI task corpus.
In other words, they said the sentence vector from supervised data (NLI) contain semantic information of input sentence than other model trained on unsupervised corpus.
First of all, befoer diving into model to encode sentence in a vector, let’s see the what NLI (natural language inference) task is :
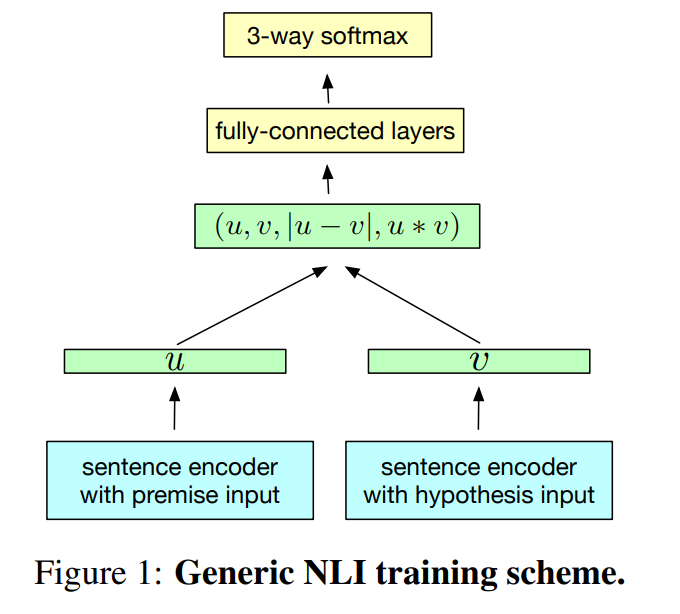
As you can see above, Models can be trained on SNLI in two different way
1) sentence encodeind-based model that explicitly separate the encoding of the indivisual sentences 2) joint methods that allow to use encoding of both sentences (to use cross-features or attention from one sentence ot the other)
They used a variety of models to generate sentence vector.
First, Bi-LSTM max pooling network
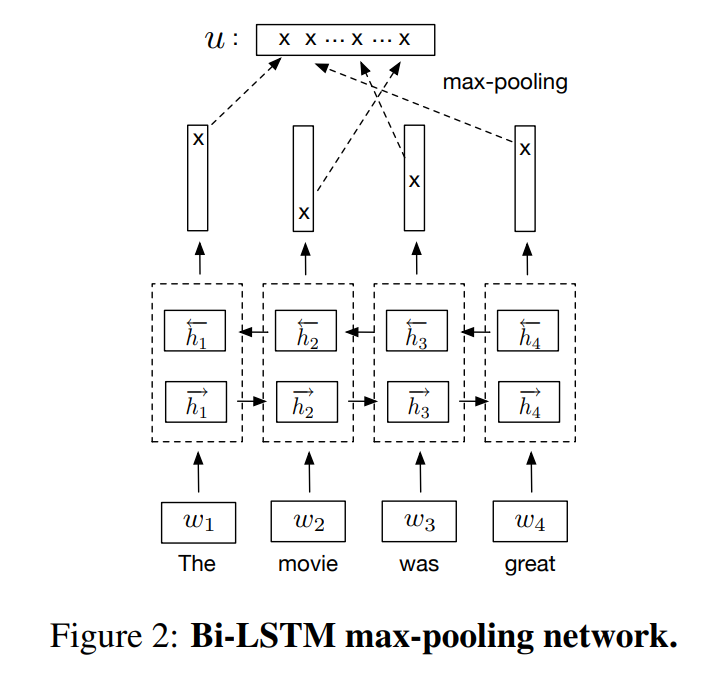
Second, inner attention network
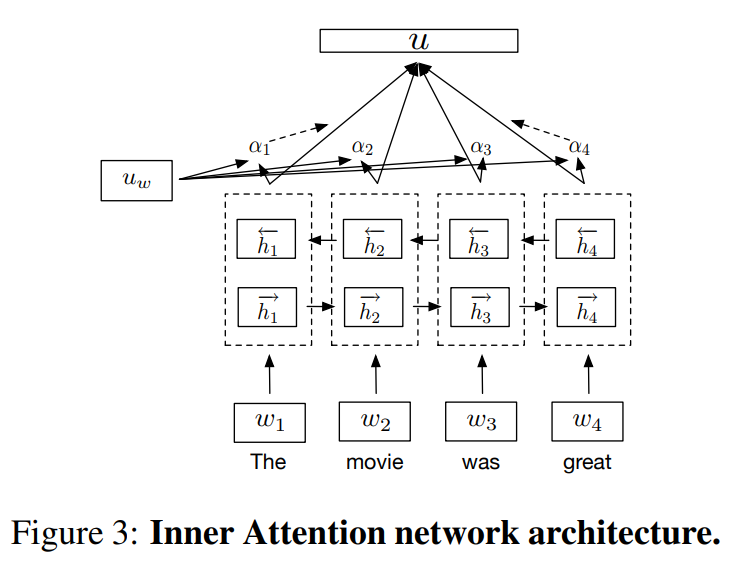
Third, Hieraachical ConvNet architecture.
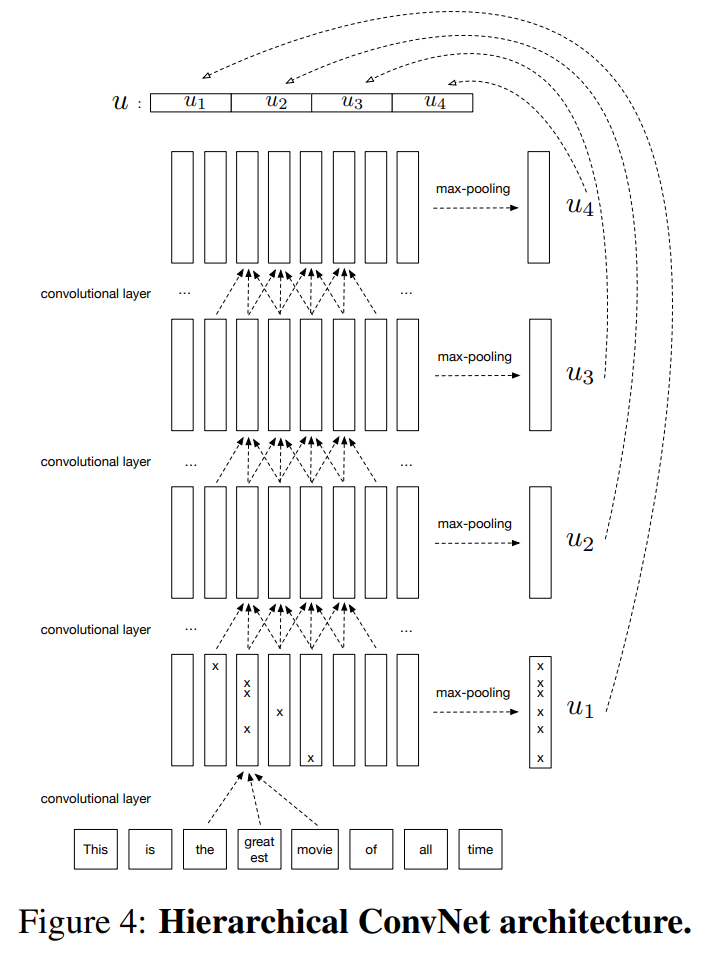
Reference
- Paper
- How to use html for alert