This is a brief summary of paper for me to study and organize it, Bidirectional Attention Flow for Machine Comprehension (Seo et al., ICLR 2017) I read and studied.
They propose the bidirectional attention flow, i.e. they separate the attention layer and modeling layer in contrary with dynamically learning the attention within modeling layer like the previous work (Bahdanau et al., 2015 ICLR)
That is, they use similarity matrix (called affinity matrix in another way) to make Context-to-query attention and Query-to-Context attention.
And then they make query-aware representation of context words with the two attentions whichs serve as input of modeling layer for QA task.
The following is their multi-stage hierarchical model structure:
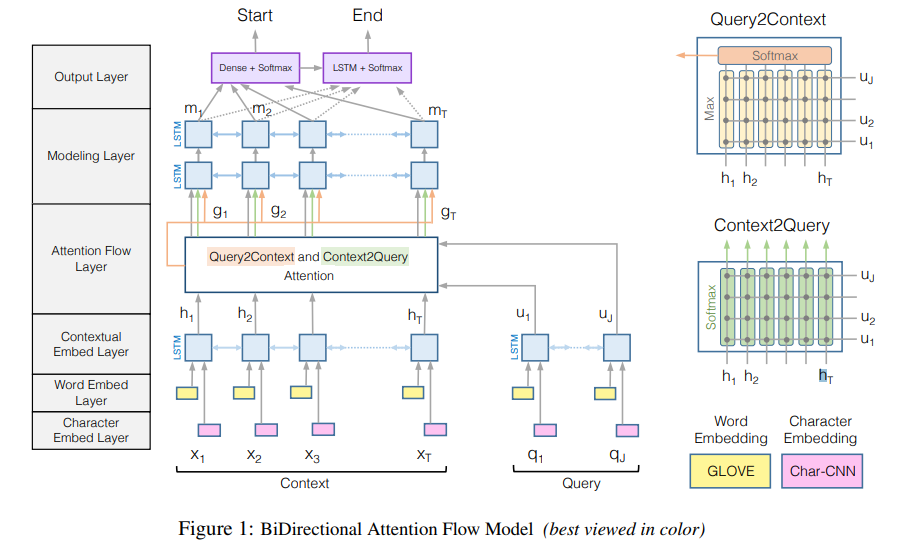
For simple explanation of their model,
Their machine comprehension model is a hierarchical multi-stage process and consists of six layers as you can see figure above.
- Character Embedding Layer maps each word to a vector space using character-level CNNs.
- Word Embedding Layer maps each word to a vector space using a pre-trained word embedding model.
- Contextual Embedding Layer utilizes contextual cues from surrounding words to refine the embedding of the words. These first three layers are applied to both the query and context.
- Attention Flow Layer couples the query and context vectors and produces a set of queryaware feature vectors for each word in the context.
- Modeling Layer employs a Recurrent Neural Network to scan the context.
- Output Layer provides an answer to the query.
The paper: Bidirectional Attention Flow for Machine Comprehension (Seo et al., ICLR 2017)
Reference
- Paper
- How to use html for alert
- For your information
- publicly avaviable code of Bidirectional Attention Flow for Machine Comprehension. Seo et al. ICLR 2017
- Bidirectional Attention Flow for Machine Comprehension. Seo et al. ICLR 2017 on Papers With Code
- Neural Machine Translation by Jointly Learning to Align and Translate. Bahdanau et al. 2015 ICLR
- What is the 1 D convolution on the StackExchange
- What is the 1 D convolution on the Stackoverflow
- Introduction to 1D Convolutional Neural Networks in Keras for Time Sequences on goodaudience blog