This is a brief summary of paper for me to study and organize it, Semi-supervised sequence tagging with bidirectional language models (Peters et al., ACL 2017) I read and studied.
They used the tokens (i.e. words) sensitive to context surrounding it.
In order to make the context sensitive representation, they used pre-training LM called LM embedding in their paper.
They show how to used a LM embedding component in the following
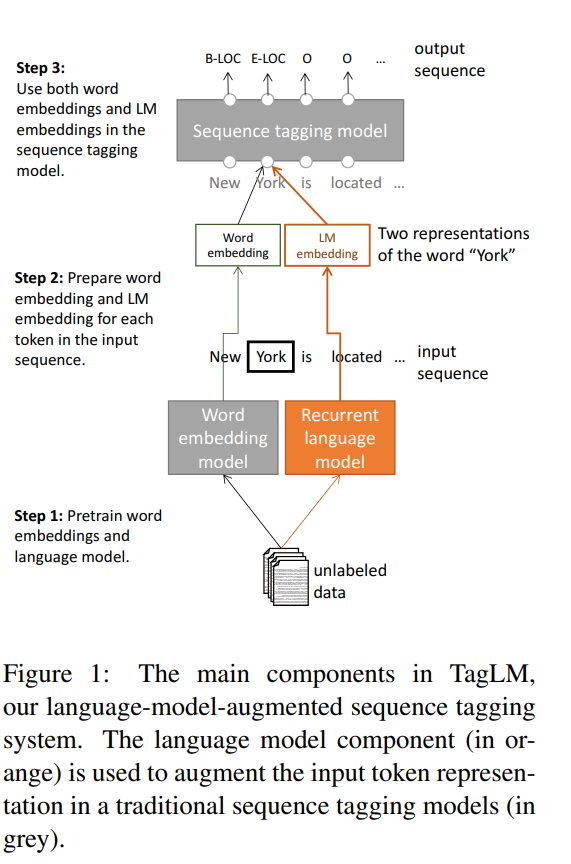
The total overview of their TagLM is as follows:
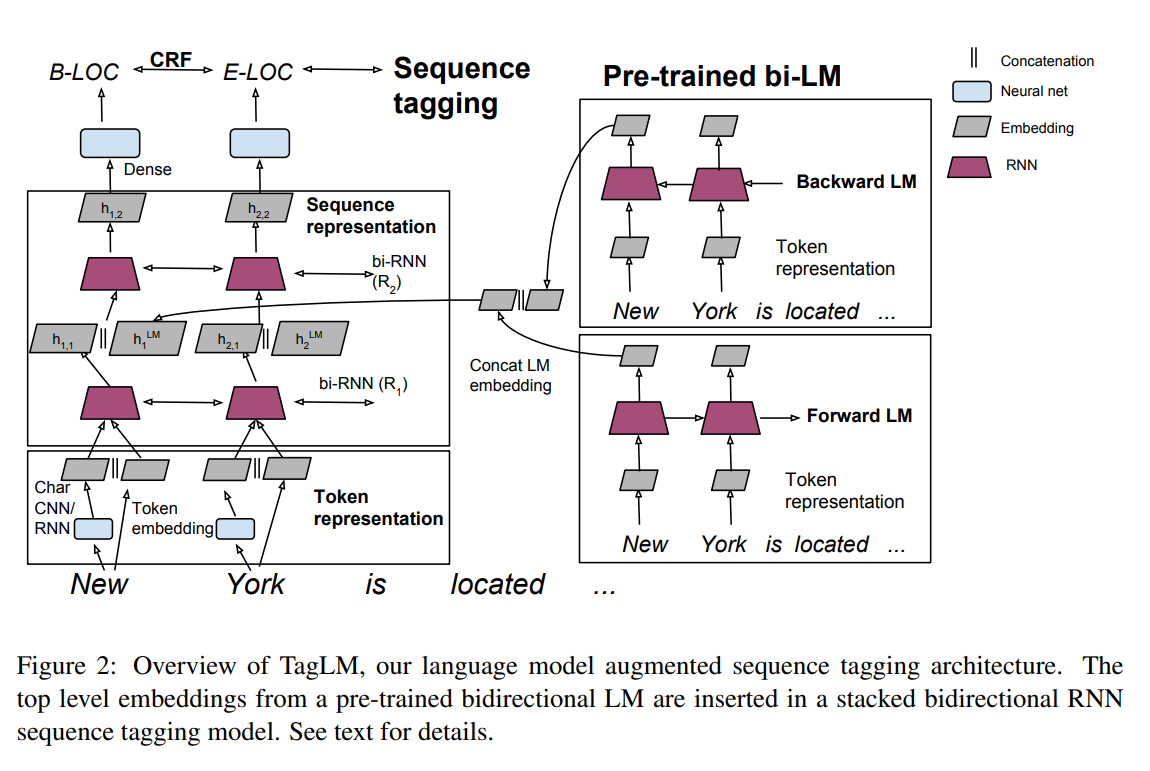
Though their idea is simple, the resuling performance is superior to the previous moethod at the moment.
Note(Abstract):
Pre-trained word embeddings learned from unlabeled text have become a standard component of neural network architectures for NLP tasks. However, in most cases, the recurrent network that operates on word-level representations to produce context sensitive representations is trained on relatively little labeled data. In this paper, they demonstrate a general semi-supervised approach for adding pretrained context embeddings from bidirectional language models to NLP systems and apply it to sequence labeling tasks. They evaluate our model on two standard datasets for named entity recognition (NER) and chunking.
Download URL:
The paper: Semi-supervised sequence tagging with bidirectional language models (Peters et al., ACL 2017)
The paper: Semi-supervised sequence tagging with bidirectional language models (Peters et al., ACL 2017)
Reference
- Paper
- How to use html for alert
- For your information