This is a brief summary of paper for me to study and organize it, Semi-supervised Sequence Learning (Dai and Le., NIPS 2015) I read and studied.
This paper showed the pretrainig with unlabeled data improve the performance of text classification.
They present two approaches that sequence autoencoder and Language modeling with recurrent nueral network.
Below is the sequence autoencoder firgure they used:
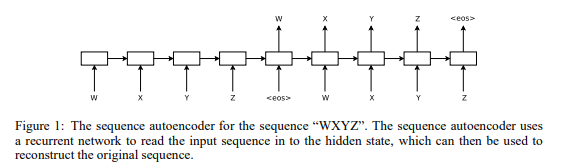
Interesting experiment to me is that they used CIFAR-10 to classify imaget with LSTM pretraining.
The input to a LSTM is an entire row of pixels and they predict the class of the image after reading the final row.
In this case, for pretraining based on Language modeling, they tranied LSTM to do next row prediction given the current row.
Another method for sequence auhoencoder autoencode the image by rows.
And the loss function during unsupervised learning is the Eucledean L2 distance between prediction and the target row.
For details, read section 4.5 Object classification experiments with CIFAR-10 in their paper.
They said
They demonstrated that a language model or a sequence autoencoder can help stabilize the learning in LSTM recurrent networks.
Also They used word dropout
Reference
- Paper
- How to use html for alert
- For your information