This is a brief summary of paper for me to study and organize it, Joint Embedding of Words and Labels for Text Classification (Wang et al., ACL 2018) I read and studied.
This paper is interested in combining word embedding with label embeddig to make word embedding efficient to a task (i.e. text classification).
They said,
A typical text classification method proceeds in three steps, end-to-end, by considering a function decomposition \(f = f_0 \circ f_1 \circ f_2\) as shown in figure above.
- \(f_0: X \rightarrow V\), the text sequence is represented as its word-embedding from V, which is a matrix of P * L.
- \(f_1: V \rightarrow z\), a compositional function \(f_1\) aggregates word embeddings into a fixed-length vector representation z.
- \(f_2: z \rightarrow y\), a classifier \(f_2\) annotates the text representation z with a label.
Below is the archtecture of their model.
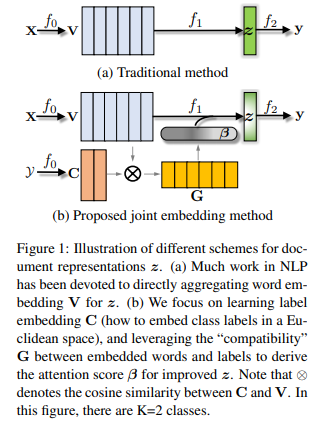
let’s see their explanation about the figure above:
- \(f_0:\) Beside embedding words, we also embed all the albels in the same space, which act as the “anchor points” of the classes to influence the refinement of word embeddings.
- \(f_1:\) The compositional function agrregates word embeddings into z, weighted by the compatibility between labels and words.
- \(f_2:\) The learning of \(f_2\) remains the same, as it directly interacts with label.
After the processes above, they classify text with cross-entorpy.
Note(Abstract):
Word embeddings are effective intermediate representations for capturing semantic regularities between words, when learning the representations of text sequences. They propose to view text classification as a label-word joint embedding problem: each label is embedded in the same space with the word vectors. They introduce an attention framework that measures the compatibility of embeddings between text sequences and labels. The attention is learned on a training set of labeled samples to ensure that, given a text sequence, the relevant words are weighted higher than the irrelevant ones. Their method maintains the interpretability of word embeddings,and enjoys a built-in ability to leverage alternative sources of information, in addition to input text sequences.
Download URL:
The paper: Joint Embedding of Words and Labels for Text Classification (Wang et al., ACL 2018)
The paper: Joint Embedding of Words and Labels for Text Classification (Wang et al., ACL 2018)
Reference
- Paper
- How to use html for alert
- For your information