This article is just brief summary of the paper, Recurrent neural network based language model (Mikolov et al., INTERSPEECH 2010).
This is for me to studying artificial neural network with NLP field.
The task that the paper applied is Language model, just it predict the conditional probability of the next word given the previous words.
let’s say the length of a sequence of words is 3, if we want to predict fourth word. the pobability of next word is conditional probability distribution is like :
- \( P(w_{3} | w_{1}, w_{2}) = P(w_{1})*P(w_{2}|w_{1})*P(w_{3}|w_{1}, w_{2}) \)
Their model estimate the conditional probability of the next word given the previous words.
as you know, their model is useful at sequential data for Recurrent neural network.
They explained with the reason that Bengio et al(2003) model has the fixed context length their model is efficient to deal with sequential data.
They said that recurrent neural network is a model which could encode temporal information implicitly for contexts with arbitrary langths.
Their model is like :
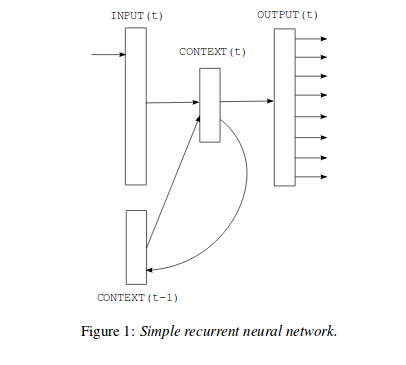
As you can check, By using recurrent connection of prior context, information can cycle inside these networks for arbitrarily long time.
I realized the on-line learning they called dynamic model.
The following is the summary about dynamic model they called in their paper.
- dynamic model : They said the network should continue training even during testing phase. They refered to such a model as dynamic.
For their dynamic model. they used the fixed learning rate(0.1) for retrainig on testing phase. while in trainig phase all data is provided to the model several times in epochs. their dynamic model gets updated just once as test data is processed on testing phase.
So their dynamic model can automatically adapt to new domains like unkonwn data.
In this case they used the standard backpropagation algorithm.
The paper: Recurrent Neural Network based Language model (Mikolov et al., INTERSPEECH 2010)
Reference
- Paper
- How to use html for alert
- For your information
- Distributed representation on O’REILLY
- Hierarchical Softmax as output activation function in Neural Network on becominghuman.ai
- Language model on Wikipedia
- Language model A Survey of the State-of-the-Art Techonology on medium
- Stackexchange on log-linear vs log-bilear
- Neural Language models and word embedding as reference
- Language Modelling and Text generation using LSTMs-Deep Learning for NLP
- Build your LSTM language model with Tensorflow on medium
- Language modeling with Deep Learning
- What’s an LSTM-LM formulation on Stackexchange
- A Recurrent Latent Variable Model for Sequential Data, Junyoung chung et al.(2016)