This is a brief summary of paper for me to study and arrange it, Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning (Jernite et al. arXiv 2017) I read and studied.
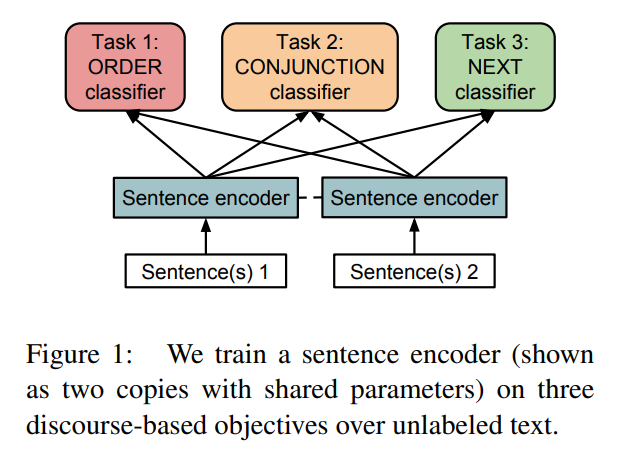
This paper proposed three objective to traing unlabeled text data as self-supervised learning.
The basis of their method is coherence relation in discourse as follows:
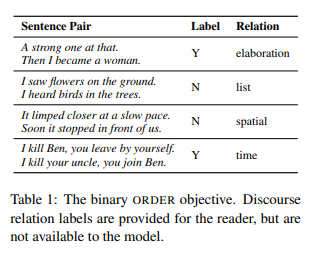
- Binary Ordering of Sentences
Many coherence relations have an inherent direction. For example, if S1 is an elaboration of S0, S0 is not generally an elaboration of S1. Thus, being able to identify these coherence relations implies an ability to recover the original order of the sentences. Our first task, which we call ORDER, consists in taking pairs of adjacent sentences from text data, switching their order with probability 0.5, and training a model to decide whether they have been switched. It should be noted that since some of these relations are unordered, it is not always possible to recover the original order based on discourse coherence alone
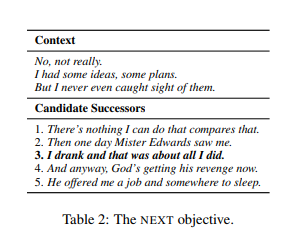
- Next Sentence
Many coherence relations are transitive by nature, so that any two sentences from the same paragraph will exhibit some coherence. However, two adjacent sentences will generally be more coherent than two more distant ones. This leads us to formulate the NEXT task: given the first three sentences of a paragraph and a set of five candidate sentences from later in the paragraph, the model must decide which candidate immediately follows the initial three in the source text.
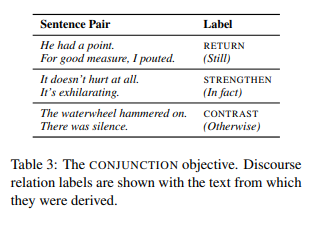
- Conjunction Prediction
Finally, information about the coherence relation between two sentences is sometimes apparent in the text: this is the case whenever the second sentence starts with a conjunction phrase.
The paper: Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning (Jernite et al. arXiv 2017)