This is a brief summary of paper for me to study and organize it, Neural Architectures for Named Entity Recognition (Lample et al., NAACL 2016) I read and studied.
They propose two method for Named Entity recognition (NER) task.
The one is bidirectinal LSTM with conditional random field.
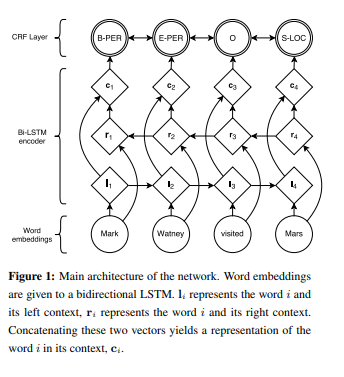
The other is stack LSTMs for chuncking method, inspired by transition-based parsing

In their methods, they used character embeddding to use e orthographic or morphological information.
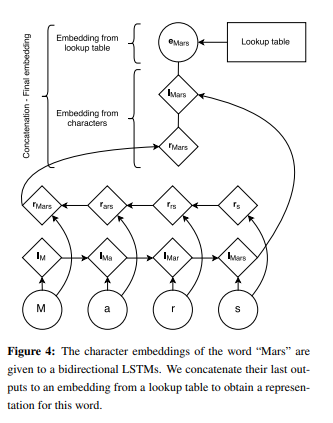
They found that the Stack-LSTM model is more dependent on character-based representations to achieve competitive performance. they hypothesize that the LSTM-CRF model requires less orthographic information since it gets more contextual information out of the bidirectional LSTMs. However, the Stack-LSTM model consumes the words one by one and it just relies on the word representations when it chunks words.
The paper: Neural Architectures for Named Entity Recognition (Lample et al., NAACL 2016)