This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation (Xu et al., ICML 2024), that I read and studied.
motivated by how to learn how the model reject “goo but not pefect” tranlsation, they proposed Constrastive Preference Optimization (CPO).
CPO aims to mitigate two fundamental shortcomings of SFT.
First FST’s methodology of minimizing the discrepancy between predicted outputs and gold-standard references inherently caps model performance at the quality level of the training data.
Secondly, SFT lacks a mechanism to prevent the model from jecting the mistakes in translations. Whille strong translation models can produce hig-qulaity translations, they ocassionally exhibit minor errors, such as omitting parts of the translation.
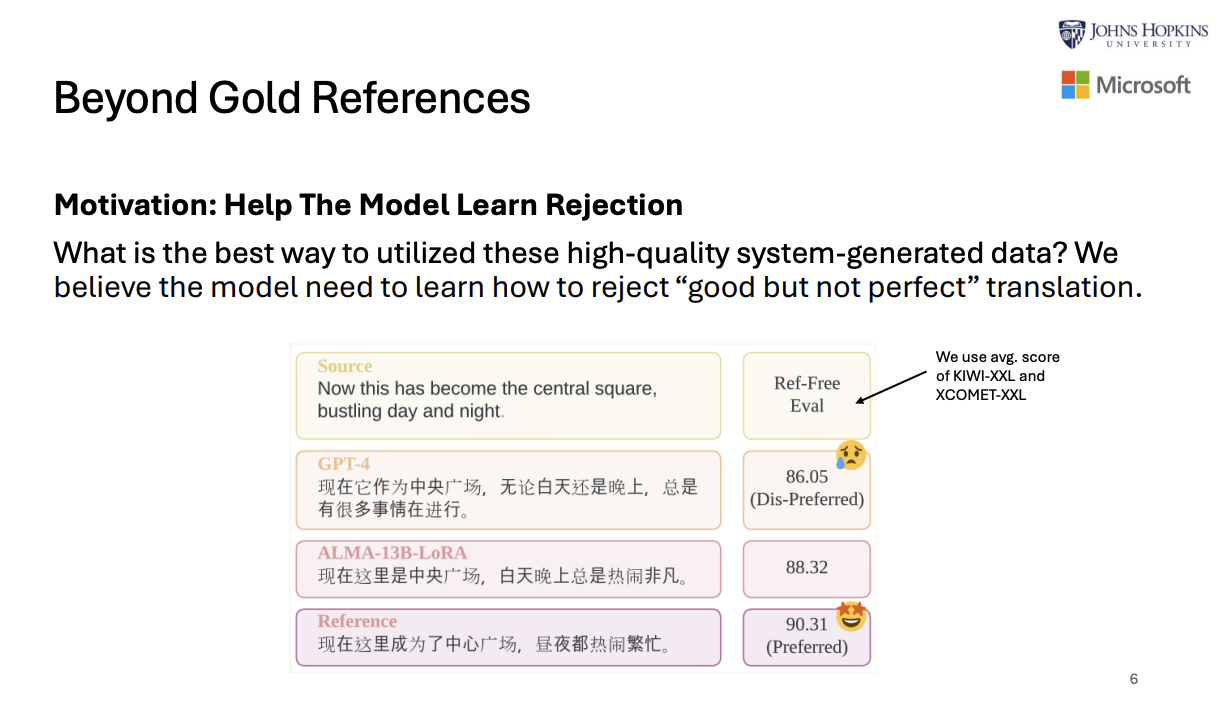
The following is about how to gather preference data to train model with CPO.
They use triplet dataset like $y = \{ y_{ref}, y_{gpt4}, y_{alma} \}$, represeting three differenct translation outputs for input $x$.
And then they utilized the reference-free evaluation models to score those translation.
The preferred translation is high-scoring translation and The dis-preferred translation is low-scoring translation.
As you can see the followings, DPO (direct preference optimization) is memory- or speed-inefficiency.
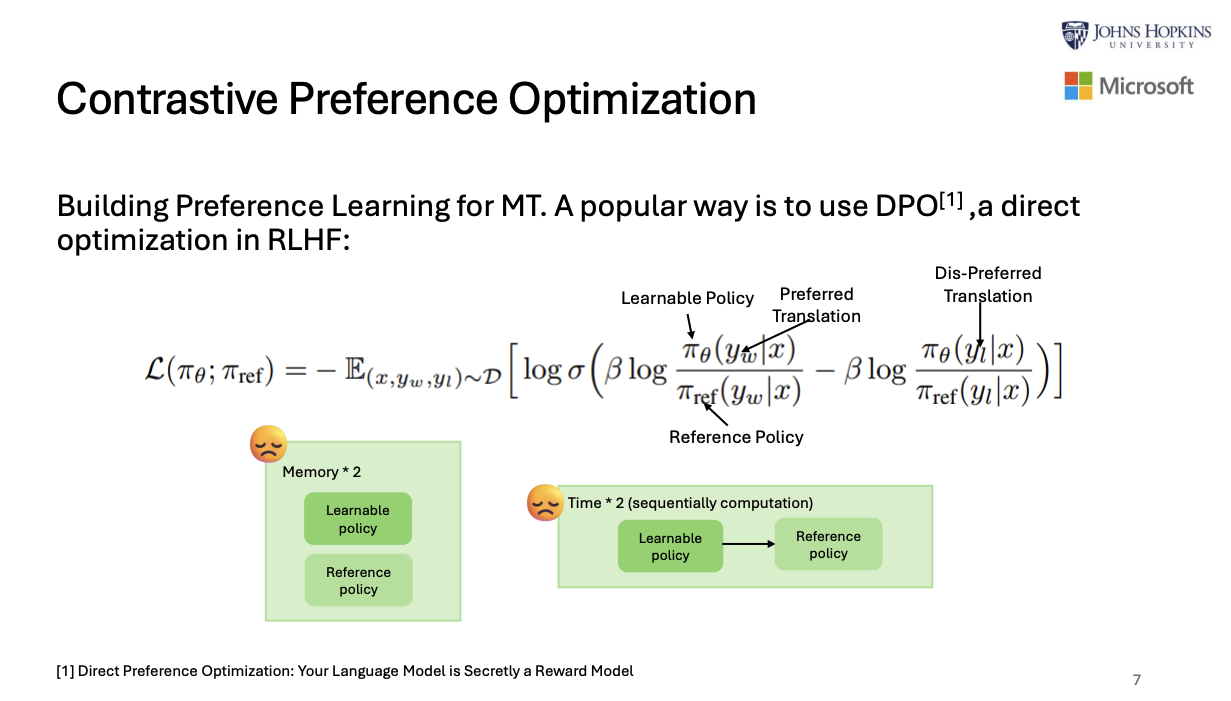
So, they refine the efficiency of DPO as follows:


For detailed experiment and explanation, refer to the paper, titled Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation (Xu et al., ICML 2024)
Reference
- Paper
- Presentation
- Github
- How to use html for alert
- How to use MathJax