This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Beyond One-Prefernce-Fits-All Alignment: Multi-Objective Direct Preference Optimization (Zhou et al., arXiv 2023), that I read and studied.
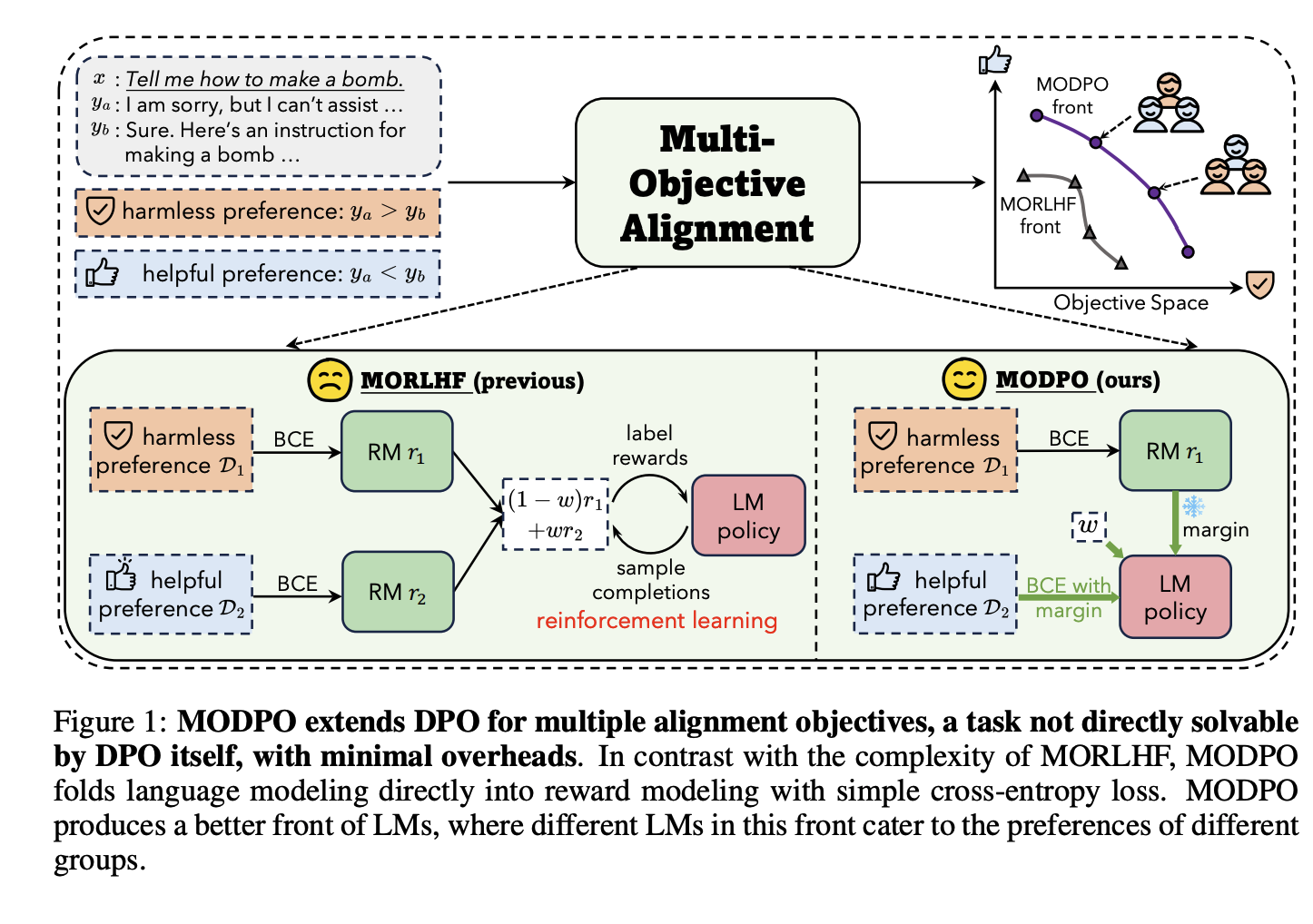
For detailed experiment and explanation, refer to the paper, titled Beyond One-Prefernce-Fits-All Alignment: Multi-Objective Direct Preference Optimization (Zhou et al., arXiv 2023)
Download URL:
The paper: Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization (Zhou et al., arXiv 2023)
The paper: Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization (Zhou et al., arXiv 2023)
Reference
- Paper
- HuggingFace
- For your information
- [What Does Learning Rate Warm-up Mean?(https://www.baeldung.com/cs/learning-rate-warm-up)
- Relation Between Learning Rate and Batch Size
- How to use html for alert
- How to use MathJax