This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Inference-Time Intervention: Eliciting Truthful Answers from a Language Model (Li et al., arXiv 2023), that I read and studied.
They propose adapting the truthfulness of LLMs using attetnion head.

ITI (Inference-time Intervention) is an alternative form of MHA, where:
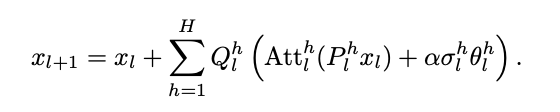
But, ITI is supervised learning, they used the activation editing.
You can see the detailed empirical analysis and experiemtn in the paper, titled Inference-Time Intervention: Eliciting Truthful Answers from a Language Model (Li et al., arXiv 2023)
For detailed experiment and explanation, refer to the paper, titled Inference-Time Intervention: Eliciting Truthful Answers from a Language Model (Li et al., arXiv 2023)
The paper: Inference-Time Intervention: Eliciting Truthful Answers from a Language Model (Li et al., arXiv 2023)
Reference
- Paper
- How to use html for alert
- How to use MathJax