This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper titled A Neural Corpus Indexer for Document Retrieval. Wang et al., arXiv 2022 that I read and studied.
Current state-of-art document retrieval solutions mainly follow an index-retrive paradigm, where the index is hard to be directly optimized for the final retrieval target.
In their paper, they aim to show that an ent-to-end deep neural newtork unifying training and indexing stages can significantly improve the recall performance of traditional methods.
In this end, they propose Neural Corpus Indexer (NCI), a sequence-of-sequence network that generates relevant document identifiers directly for a designated query.
Document retrieval and ranking are two key stages for a standard web search engine. First, the document retrieval stage retrieves candidate documents relevant to the query, and then, the ranking stage gives a more precise ranking score for each document.
The ranking score stage is often fulfiled by a deep neural network, taking each pair of query and document as input and predicting their relevance score.
Nevertheless, a precise ranking model is very costly, while typcially only a hundred or thousand candidates per query are affordable in an onlin system.
As a result, the recall performance of the document retrieval stage is very crucial to the effectiveness of web search engines.
They show that the traditional text retrieval frameworks can be fundamentally changed by a unified deep neural network with tailored designs.
To this end, they propose a Neural Corpus Indexer (NCI), which supports end-to-end document retrieval by a sequence-to-sequence neural network.
The model takes a user query as input, generates the query embedding through the encoder, and outputs the identifiers of relevant documents using the decoder.
It can be trained by both ground-truth and augmented query-document pairs. During inference, the top N documents are retrieved via beam search based on the decoder
NCI can be served as an end-to-end retrieval solution while releasing the burden of re-reanking for a long candidate list.
Furthermore, the invention of Neural Corpus Indexer is also promising from the perspective of system design.
Ranking adn query-answering modules are already implemented by neural networks, NCI finishes the last piece of puzzzle of for the next-generation information retrieval system based on a unified differntiable model architecture. This reduces the dependency among different sub-modules
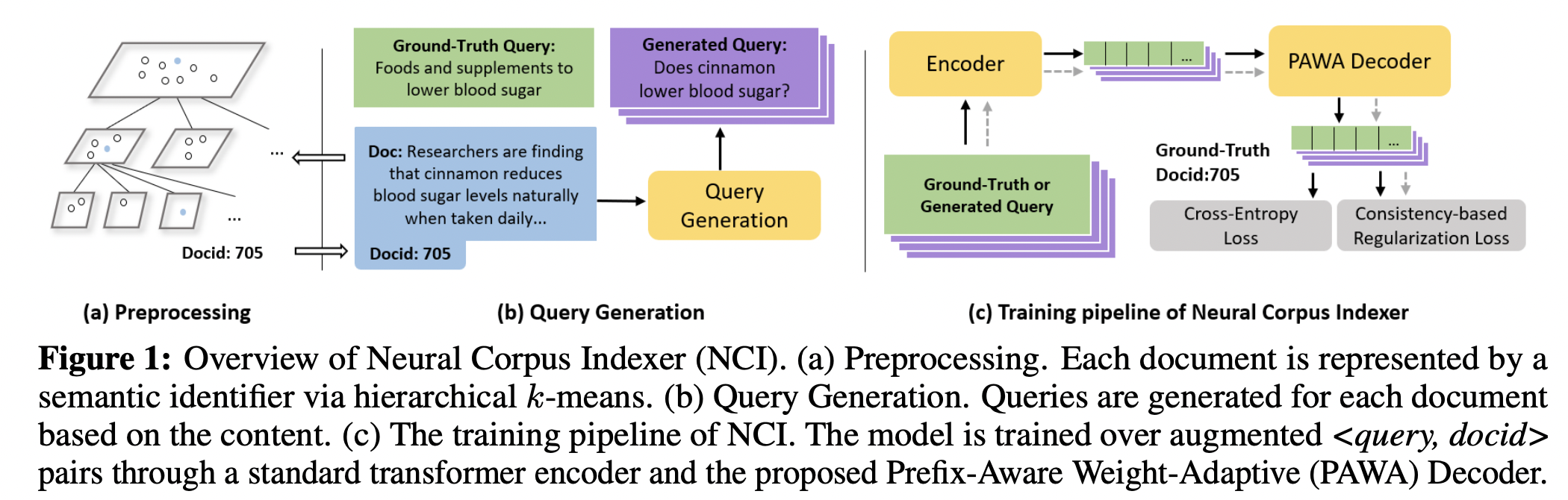
The Neural Corpus indexer (NCI) is a sequence-to-sequence neural network model. The model takes a query as input and outputs the most relevant document identifier (docid), which can be trained by a large collection of <query, docid>
As shown in Figure 1, NCI is composed of three components, including Query Generation, Encoder, and Prefix-Aware Weight-Adaptive (PAWA) Decoder.
They showed that NCI has a potentential to be served as end-to-end solution that replaces the entire index-retrieve-rank pipeline in traditional web search engines.
If you want to know and understand the detailed information about NCI, Read the paper which titled A Neural Corpus Indexer for Document Retrieval. Wang et al., arXiv 2022
The paper's title is known as A Neural Corpus Indexer for Document Retrieval. (Wang et al., arXiv 2022)
Reference
- Paper
- How to use html for alert
- How to use MathJax