This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper titled Transformer Memory as a Differentiable Search Index. Tay et al., arXiv 2022 that I read and studied.
They showed that information retrieval can be accomplished with a single Transformer because all information about the corpus is encoded in the parameters of the model.
To this end, they introduece the Differentialbe Serach Index (DSI), a pradigm that learns a text-to-text model that maps string queriesy directly to relevant docids (i.e. document identifiers) the process of which dramatically simplifies the whole retrieval process.
In their research, they tried to study variations in how documents and their identifiers are represented, variations in training precedures, and the interplay between models and corpus size.
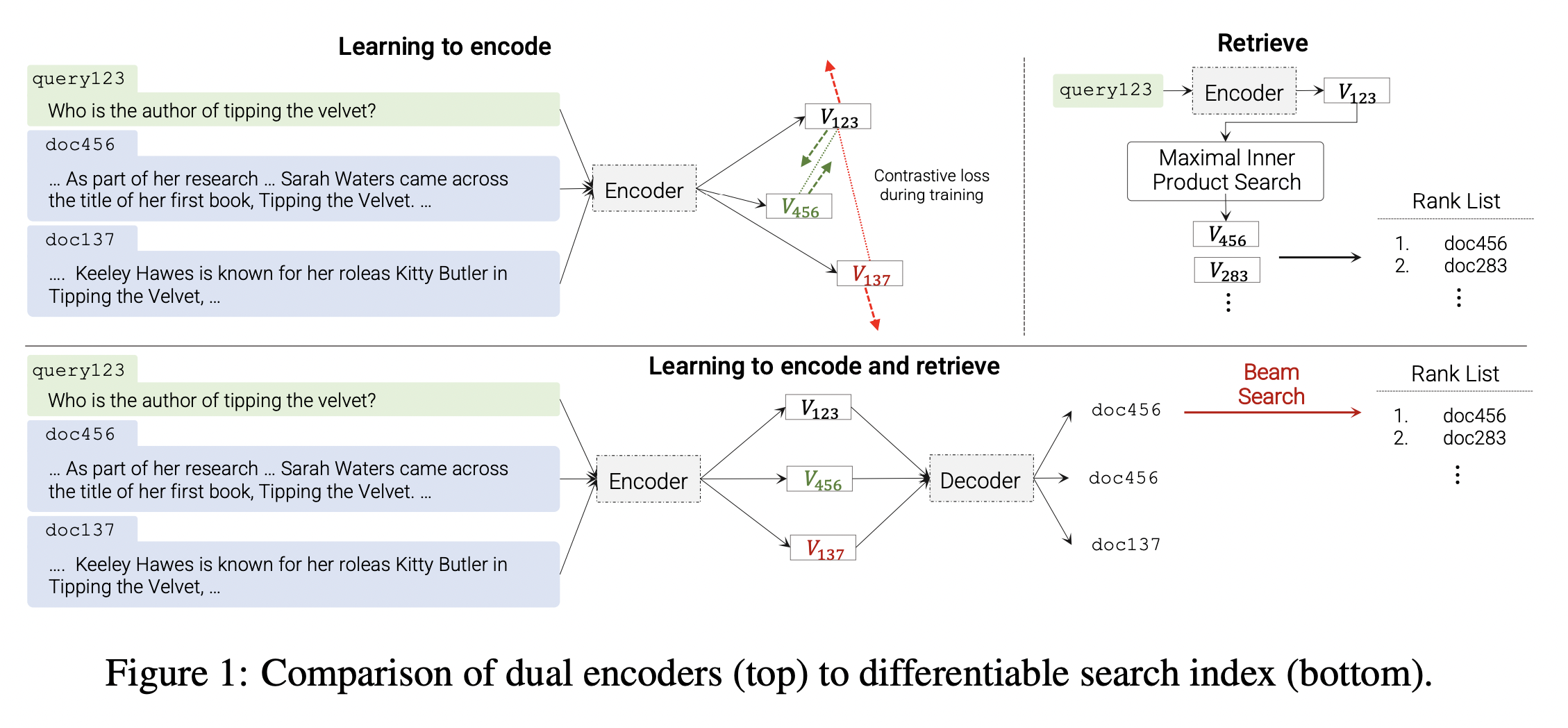
They propose an architecture called differentiable search index (DSI) with a larage pre-trained Transformer wherein a sequence-to-sequence (seq2seq) learning system is used to directly map a query q to a relevant docid j ∈ Y, after saying as follows in the bottom half of Figure 1.
- Information retrieval (IR) systems map a user query q ∈ Q to a ranked list of relevant documents {d1, . . . , dn} ⊆ D, typically represented by integers or short strings called document identifiers (docids).
- The most widely used IR approaches are based on pipelined retrieve-then-rank strategies.
- For retrieval, approaches based on inverted indexes or nearest neighbor search are common when contrastive learning based dual encoders (DEs)is used.
In other words, as inference tiems, the trained model takes as input a text query q and outputs a docid j.
The DSI architecture is much simpler than a DE (see Table 1). A DE system fixes a search procedure (MIPS) and learns internal representations that optimize performance for that search procedure; in contrast, a DSI system contains no special-purpose fixed search procedure, instead using standard model inference to map from encodings to docids.
Of particular interest to the machine learning community, as Table 1 shows, in DSI all aspects of retrieval are mapped into well-understood ML tasks. This may lead to new potential approaches to solving long-standing IR problems. As one example, since indexing is now a special case of model training, incrementally updating an index becomes a special case of model updating
To sum up, Let’s see a sereis of decision about information retrieval system.

In other words, the core idea behind the proposed Differentiable Search Index (DSI) is to fully parameterize traditionally multi-stage retrieve-then-rank pipelines within a single neural model.
To do so, DSI models must support two basic modes of operation:
• Indexing: a DSI model should learn to associate the content of each document dj with its corresponding docid j. This paper utilizes a straightforward sequence-to-sequence (seq2seq) approach that takes document tokens as input and generates identifiers as output.
• Retrieval: Given an input query, a DSI model should return a ranked list of candidate docids. Here, this is achieved with autoregressive generation.
If you want to know and understand the detailed information about DSI, Read the paper which titled Transformer Memory as a Differentiable Search Index. Tay et al., arXiv 2022
The paper's title is known as Transformer Memory as a Differentiable Search Index. (Tay et al., arXiv 2022)
Reference
- Paper
- How to use html for alert
- How to use MathJax