This is a brief summary of paper for me to study and organize it, Deep RNNs Encode Soft Hierarchical Syntax (Blevins et al., ACL 2018) that I read and studied.
They show that the internal representations of RNNs trained on a variety of NLP tasks encode these syntactic features without explicit supervision. And they found that deeper layers in each model capture notions of syntax that are higher-level and more abstract, in the sense that higher-level constituents cover a larger span of the underlying sentence.
These findings suggest that models trained on NLP tasks are able to induce syntax even when direct syntactic supervision is unavailable.
For experiment, They desing how to experiment for check if the RNN induced syntax information.
Given a model that uses multi-layered RNNs, they collect the vector representation \(x^{l}_{i}\) of each word \(i\) at each hidden layer \(l\).
To determine what syntactic information is stored in each word vector, they try to predict part-of-speech from the vector alone.
Specifically, they predict the word’s part of speech (POS), as well as the first (parent), second (grand-parent), and third level (great-grandparent) constituent labels of the given word.
Consequently, they run a series of prediction tasks on the internal representations of deep NLP models as follows:

They evaluate how well a simple feedforward classifier can detect these syntax features from the word representations produced by the RNN layers from deep NLP models trained on the tasks of dependency parsing, semantic role labeling, machine translation, and language modeling.
The prediction task to identfy if these RNNs are able to induce syntax without explicit linguaistic supervision is implement on the RNN models above.
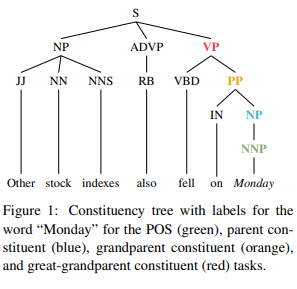
Fro predictions task, they attempt to predict the POS tag and the parent, grandparent, and great-grandparent constituent labels of that word.
They found that the representations taken from deeper layers of the RNNs perform better on higher-level syntax tasks than hose from shallower layers, suggesting that these recurrent models induce a soft hierarchy over the encoded syntax.
They said as follows
these results provide some insight as to why deep RNNs are able to model NLP tasks without annotated linguistic features.
For detailed experiment analysis, you can found in Deep RNNs Encode Soft Hierarchical Syntax (Blevins et al., ACL 2018)