This is a brief summary of paper for me to study and organize it, Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (McCoy et al., ACL 2019) that I read and studied.
They said
Statistical learner such as neural networks closely track the statistical regularities in their training sets. This process makse them vulnerable to adapting heuristics that are valid for frequent cases but fail on less frequent ones.
Thus, they investigated three such heuristics that they hypothesize NLI models are likely to learn.
They introdue HANS dataset to evaluate whether NLI models do behave consistently with these heuristics.
The heuristics is as follows:
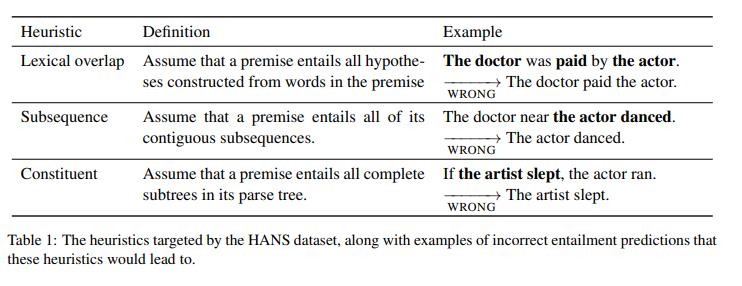
Statistical learner such ash neural networks excel at learning the statistical patterns in a training set and applying them to test cases drawn from the same distribution as the training examples.
This strength can also be a weakness: statistical learners such as standard neural network architectures are prone to adopting shallow heuristics that succeed for the majority of training examples, instead of learning the underlying generalizations that they are intended to capture.
This issue has been documented across domains in artificial intelligence.
In this paper, they addressed this issue in the domain of natural language inference (NLI), the task of determining whether a premise sentence entails a hypothesis sentence.
For example, a model might assign a label of contradiction to any input containing the word not, since not often appears in the examples of contradiction in standard NLI training sets. The focus of our work is on heuristics that are based on superficial syntactic properties.
Consider the following sentence pair, which has the target label entailment:
Premise: The judge was paid by the actor.
Hypothesis: The actor paid the judge.
An NLI system that labels this example correctly might do so not by reasoning about the meanings of these sentences, but rather by assuming that the premise entails any hypothesis whose words all appear in the premise.
So they introduce a new evaluation set called HANS (Heuristic Analysis for NLI Systems), designed to diagnose the use of such fallible structural heuristics as follows:
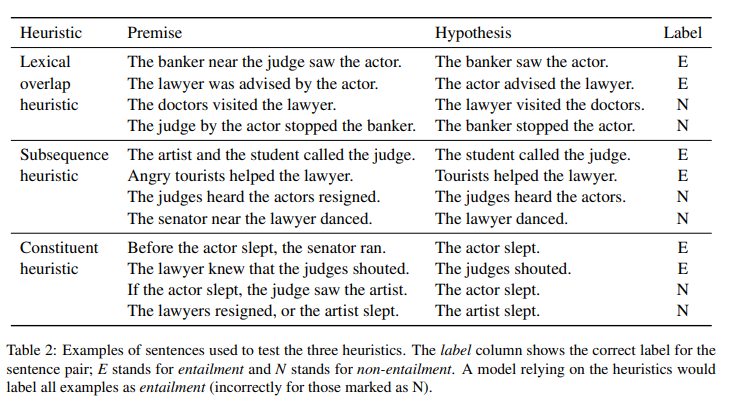
We target three heuristics, defined in figures above.
While these heuristics often yield correct labels, they are not valid inference strategies because they fail on many examples.
They find that four existing NLI models perform very poorly on HANS, suggesting that their high accuracies on NLI test sets may be due to the exploitation of invalid heuristics rather than deeper understanding of language.
However, these models performed significantly better on both HANS and on a separate structure-dependent dataset when their training data was augmented with HANS-like examples.
Overall, Their results indicate that, despite the impressive accuracies of state-of-the-art models on standard evaluations, there is still much room to improve the model.
So they said :
it is important to make dataset to determine whether models are learning what they are intended to learn.
If you know the detailed analysis of NLI task, see the paper Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (McCoy et al., ACL 2019)
The paper: Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (McCoy et al., ACL 2019)
Reference
- Paper
- How to use html for alert