This is a brief summary of paper for me to study and organize it, Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss (Plank et al., ACL 2016) I read and studied.
They performed the experiment on POS tagging with multiple languages.
They used character embedding and byte embedding to handle rare words as follows:
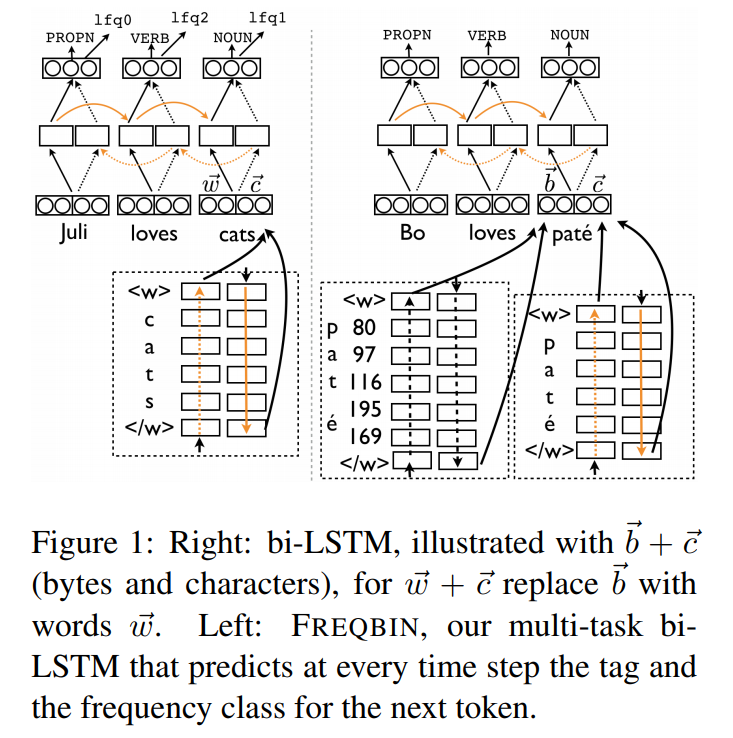
on their model, they train the bi-LSTM tagger to predict both the tags of the sequence, as well as a label that represents the log frequency of the next token as estimated from the training data
log frequency label : \(int(log(fre_{train}(w)))\)
They measured the performance with respect to label noise, data size, and rare word.
The result showed
- For rare word, the rare token benefits from sub-token representation
- For data size, the bi-LSTM model is better with more data but the TNT, based on a second order HHM, is better with little data. The bi-LSTM model always wins over CRF.
- For label noise, bi-LSTMs are less robust, showing higher drops in accuracy compared to TNT.
Note(Abstract):
Bidirectional long short-term memory (biLSTM) networks have recently proven successful for various NLP sequence modeling tasks, but little is known about their reliance to input representations, target languages, data set size, and label noise. They address these issues and evaluate bi-LSTMs with word, character, and unicode byte embeddings for POS tagging. They compare bi-LSTMs to traditional POS taggers across languages and data sizes. They also present a novel biLSTM model, which combines the POS tagging loss function with an auxiliary loss function that accounts for rare words. The model obtains state-of-the-art performance across 22 languages, and works especially well for morphologically complex languages. Their analysis suggests that biLSTMs are less sensitive to training data size and label corruptions (at small noise levels) than previously assumed.
Reference
- Paper
- How to use html for alert