This is a brief summary of paper for me to study and organize it, Pointing the Unknown Words. (Gulcehre et al., ACL 2016) I read and studied.
Words are the basic input/output units in most of the NLP systems, and thus the ability to cover a large number of words is a key to building a robust NLP system.
However, considering that (i) the number of all words in a language including named entities is very large and that (ii) language itself is an evolving system (people create new words), this can be a challenging problem.
First of all, there is usually neural network-based NLP system using softmax output layer where each of the output dimension corresponds to a word in a predefined word-shortlist.
But it is not efficient, because computing high dimensional softmax is computationally expensive.
So in practice the shortlist is limited to have only topK most frequent words in the training corpus. All other words are then replaced by a special word, called the unknown word (UNK).
The shortlist approach has two fundamental roblems.
The first problem, which is known as the rare word problem, is that some of the words in the shortlist occur less frequently in the training set and thus are difficult to learn a good representation, resulting in poor performance.
Second, it is obvious that we can lose some important information by mapping different words to a single dummy token UNK. Even if we have a very large shortlist including all unique words in the training set, it does not necessarily improve the test performance, because there still exists a chance to see an unknown word at test time. This is known as the unknown word problem.
In addition, increasing the shortlist size mostly leads to increasing rare words due to Zipf’s Law.
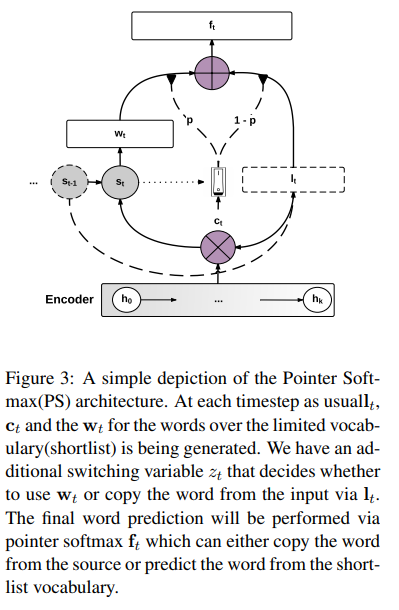
As per this problem, this paper proposed the way to point the unknown word from source text to target text.
So they used pointer softmax which consists of two types, location softmax and shortlist softmax as follows.
Reference
- Paper
- How to use html for alert
- For information