This is a brief summary of paper for me to study and organize it, Attention-Guided Answer Distillation for Machine Reading Comprehension (Hu et al., EMNLP 2018) I read and studied.
This paper proposed a simple way to distill knowledge from teacher to student.
The teacher model is large model, an anesmble model which is comprised of 12 single models with the indentical architecture but different initial parameter to obtain the ensemble.
Their model is robust to adversarial attack on Machine Reading Comprehension task.
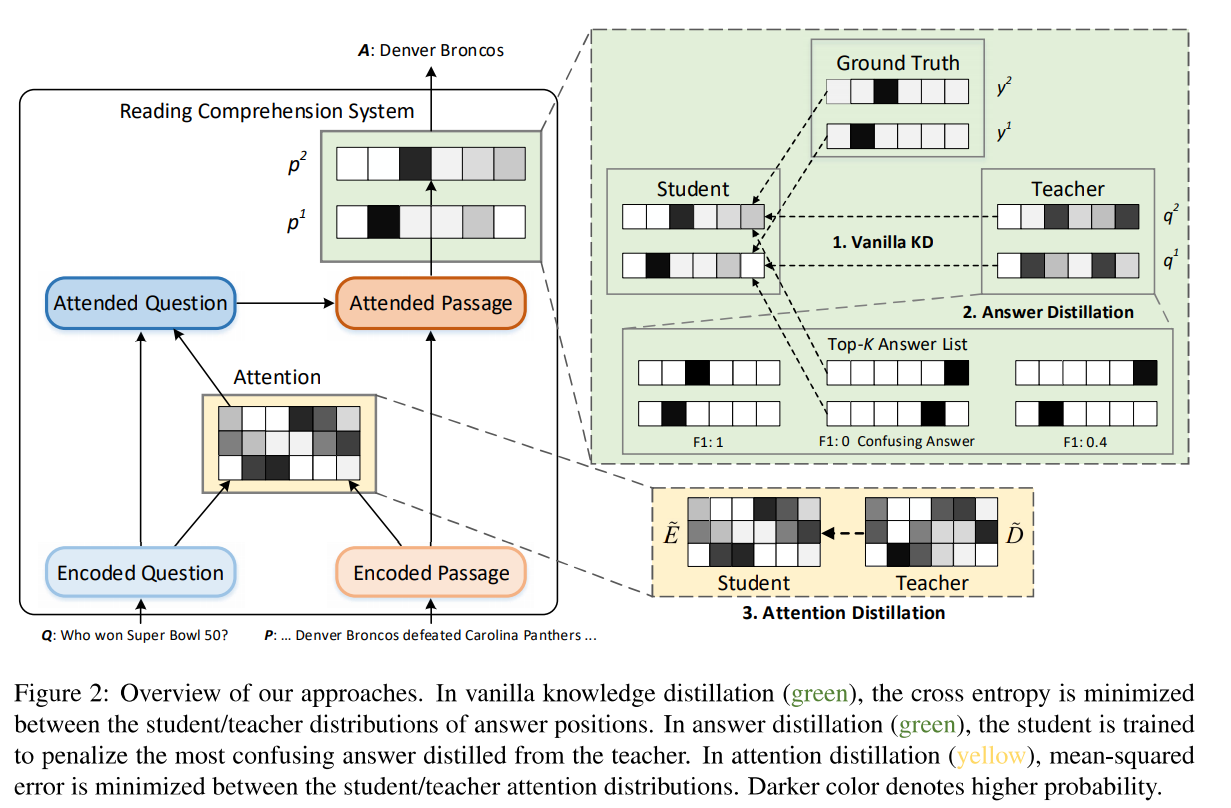
They suggest three ways to distill knowlege (i.e. Vanilla Knowledge Distillation, Answer Distillation, and Attention Distillation)
The vanilla knowledge distillation denote that instead of ground truths it uses out distribution from teacher. i.e. Vanilla knowledge distillation allows the student to learn knowledge from teacher.
Answer distillation is used to prevent the student from make an over-confidence to confusing answer.
Attention distillation is similar to distill intermediate representations to provide additional supervised signal for training the student network, However it used attention information in place of the intermediate representation.
The following is overview of their appproach:
The paper: Attention-Guided Answer Distillation for Machine Reading Comprehension (Hu et al., EMNLP 2018)