This is a brief summary of paper for me to study and arrange for Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. (Artetxe and Schwenk., arXiv 2019) I read and studied.
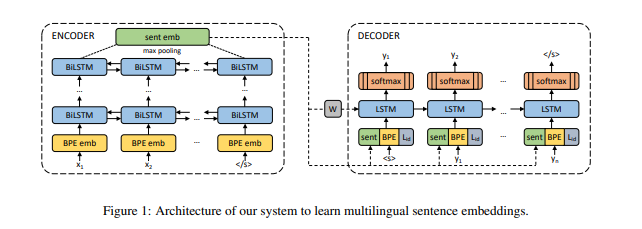
This paper propose sentence embedding by using a BiLSTM encoder sharing a large number of languages as follows:
The interesting point they used is byte-pair encoding vocabulary with 50K operations, which is learned on the concatenation of all training corpora.
Note(Abstract):
They introduce an architecture to learn joint multilingual sentence representations for 93 languages, belonging to more than 30 different families and written in 28 different scripts. Their system uses a single BiLSTM encoder with a shared BPE vocabulary for all languages, which is coupled with an auxiliary decoder and trained on publicly available parallel corpora. This enables us to learn a classifier on top of the resulting embeddings using English annotated data only, and transfer it to any of the 93 languages without any modification. Their experiments in cross-lingual natural language inference (XNLI dataset), cross-lingual document classification (MLDoc dataset) and parallel corpus mining (BUCC dataset) show the effectiveness of their approach. They also introduce a new test set of aligned sentences in 112 languages, and show that our sentence embeddings obtain strong results in multilingual similarity search even for low-resource languages. Their implementation, the pretrained encoder and the multilingual test set are available at https://github.com/facebookresearch/LASER.