This is a brief summary of paper for me to note it, Meta-Learning for Low-Resource Neural Machine Translation (Gu et al., EMNLP 2018)
They suggest application from model-agnostic meta-learning to neuarl machine tralsation.
There are two categories of meta-learning:
-
learning a meta-policy for updating model parameters
-
learning a good parameter initialization for fast adaptation
They implement translation task adapting second one of two categories below to neural machine translation.
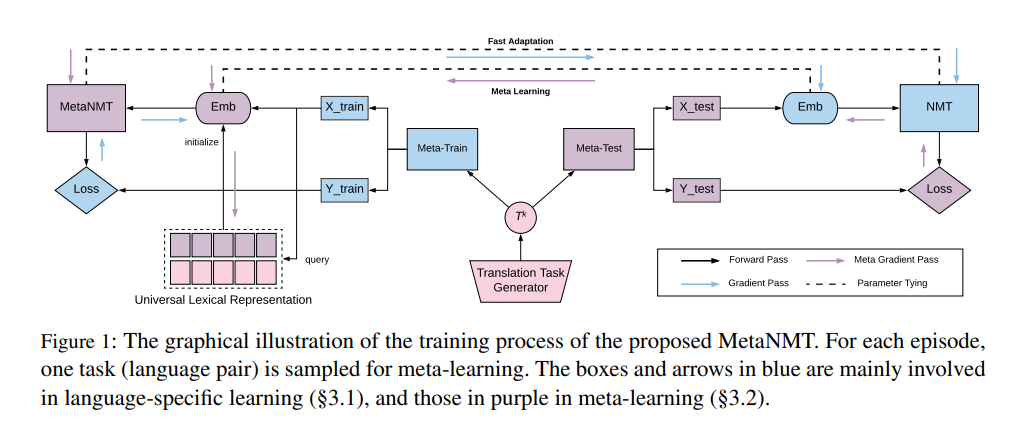
In this paper, they follow up on these latest approaches based on multilingual NMT and propose a meta-learning algorithm for low-resource neural machine translation. We start by arguing that the recently proposed model-agnostic meta-learning algorithm could be applied to low-resource machine translation by viewing language pairs as separate tasks. This view enables us to use MAML to find the initialization of model parameters that facilitate fast adaptation for a new language pair with a minimal amount of training examples.
Furthermore, the vanilla MAML however cannot handle tasks with mismatched input and output. They use the universal lexical representation and adapting it for the meta-learning scenario.
They extensively evaluate the effectiveness and generalizing ability of the proposed meta-learning algorithm on low-resource neural machine translation. We utilize 17 languages from Europarl and Russian from WMT as the source tasks and test the meta-learned parameter initialization against five target languages (Ro, Lv, Fi, Tr and Ko), in all cases translating to English.
There is I/O mismatch across language pairs.
One major challenge that limits applying meta-learning for low resource machine translation is that the approach outlined above assumes the input and output spaces are shared across all the source and target tasks.
This, however, does not apply to machine translation in general due to the vocabulary mismatch across different languages.
In multilingual translation, this issue has been tackled by using a vocabulary of sub-words or characters shared across multiple languages.
This surface-level sharing is however limited, as it cannot be applied to languages exhibiting distinct orthography (e.g., IndoEuroepan languages vs. Korean.)
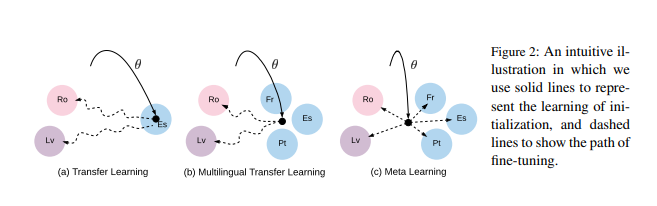
Illustration In Fig. 2, they contrast transfer learning, multilingual learning and meta-learning using three source language pairs (Fr-En, Es-En and Pt-En) and two target pairs (Ro-En and Lv-En).
Transfer learning trains an NMT system specifically for a source language pair (Es-En) and fine-tunes the system for each target language pair (RoEn, Lv-En). Multilingual learning often trains a single NMT system that can handle many different language pairs (Fr-En, Pt-En, Es-En), which may or may not include the target pairs (Ro-En, LvEn).
If not, it finetunes the system for each target pair, similarly to transfer learning. Both of these however aim at directly solving the source tasks.
On the other hand, meta-learning trains the NMT system to be useful for fine-tuning on various tasks including the source and target tasks.
This is done by repeatedly simulating the learning process on low-resource languages using many high-resource language pairs (Fr-En, Pt-En, Es-En).
The paper: Meta-Learning for Low-Resource Neural Machine Translation (Gu et al., EMNLP 2018)
Reference
- Paper
- How to use html for alert
- For your information