This is a brief summary of paper for me to study and arrange for Contextual String Embeddings for Sequence Labeling (Akbik et al., COLING 2018) I read and studied.
They propose the pre-training model to language model, most of research train language model based on word level.
However, they train the model language model dealing with a sentence as a character sequence.
They propose a novel type of contextualized characterlevel word embedding which they hypothesize to combine the best attributes of the embeddings; namely, the ability to (1) pre-train on large unlabeled corpora, (2) capture word meaning in context and therefore produce different embeddings for polysemous words depending on their usage, and (3) model words and context fundamentally as sequences of characters, to both better handle rare and misspelled words as well as model subword structures such as prefixes and endings.
To sum up , they present a method to generate such a contextualized embedding for any string of characters in a sentential context, and thus refer to the proposed representations as contextual string embeddings as follows:
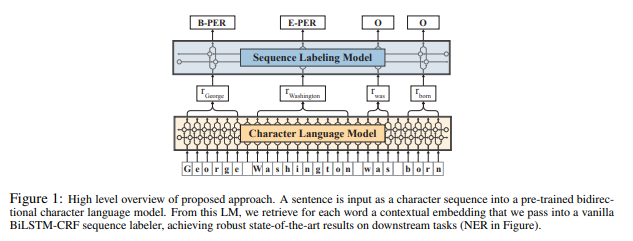
The following show they extracter wored embedding from character sequence language model.
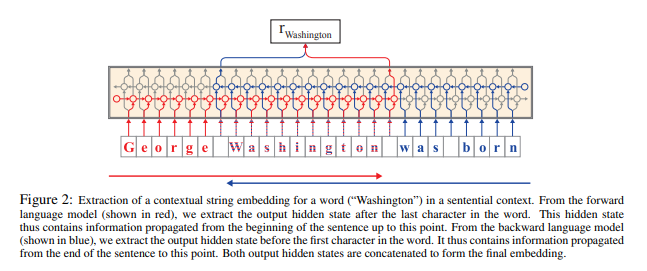
The paper: Contextual String Embeddings for Sequence Labeling (Akbik et al., COLING 2018)
Reference
- Paper
- How to use html for alert