This is a brief summary of paper for me to study and arrange for Attending to Characters in Neural Sequence Labeling Models (Rei et al., COLING 2016) I read and studied.
This paper implemented seqeunce labeling task on a range of the benchmark dataset and then they extend the character embedding to word-based model for unseen or rare words.
They said the conventional model used feature engineering, integrating gazetteers for named entity recognization or using feature from morphological analyzer in POS-tagging.
They first described the word-level neural network for sequence labeling like this:
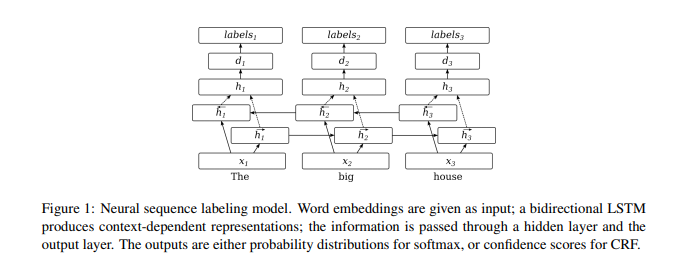
Next, They describe how to extend character embedding to word-level model.
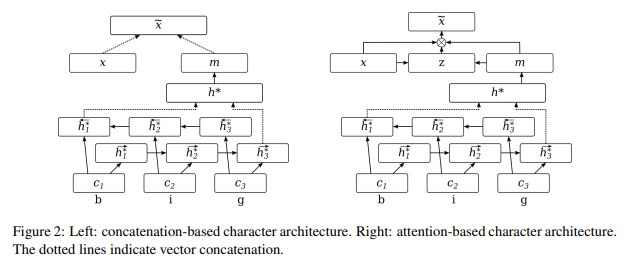
As you can see above, one possibel approach is to concatenate the two vectors and use this asthe new word-level representataion like Left in Figure2.
The other possible approach construct the word representation from characters using Bidirectional LSTM and the last hidden states are used to creat vector m for input word as Figure 2 above.
Instead of concatinating this with word embedding like Left in Figure 2, two vectors are added together using a weighted sum, where the weights are predicted by two-layer network.
This weighted sum approach allows the model to dynamically decide how much information to use from the character-level component or from the word embedding.
This decision is done for each feature separately, which adds extra flexiblity – for example, words with regular suffixes can share some character-level features, whereas irregular words can store exceptions into word embeddings.
Furthermore, previously unknown words are able to use character-level regularities whenever possible, and are still able to revert to using the generic OOV token when necessary
They used datasets below:
CoNLL00: The CoNLL-2000 dataset is a frequently used benchmark for the task of chunking. Wall Street Journal Sections 15-18 from the Penn Treebank are used for training, and Section 20 as the test data.
CoNLL03: The CoNLL-2003 corpus was created for the shared task on language-independent NER. They use the English section of the dataset, containing news stories from the Reuters Corpus1.
PTB-POS: The Penn Treebank POS-tag corpus contains texts from the Wall Street Journal, annotated for part-of-speech tags. The PTB label set includes 36 main tags and an additional 12 tags covering items such as punctuation.
FCEPUBLIC: The publicly released subset of the First Certificate in English (FCE) dataset contains short essays written by language learners and manual corrections by examiners. They use a version of this corpus converted into a binary error detection task, where each token is labeled as being correct or incorrect in the given context.
BC2GM: The BioCreative II Gene Mention corpus consists of 20,000 sentences from biomedical publication abstracts and is annotated for mentions of the names of genes, proteins and related entities using a single NE class.
CHEMDNER: The BioCreative IV Chemical and Drug NER corpus consists of 10,000 abstracts annotated for mentions of chemical and drug names using a single class.
JNLPBA: The JNLPBA corpus consists of 2,404 biomedical abstracts and is annotated for mentions of five entity types: CELL LINE, CELL TYPE, DNA, RNA, and PROTEIN. The corpus was derived from GENIA corpus entity annotations for use in the shared task organized in conjuction with the BioNLP 2004 workshop.
GENIA-POS: The GENIA corpus is one of the most widely used resources for biomedical NLP and has a rich set of annotations including parts of speech, phrase structure syntax, entity mentions, and events. Here, they make use of the GENIA POS annotations, which cover 2,000 PubMed abstracts (approx. 20,000 sentences). They use the same 210-document test set, and additionally split off a sample of 210 from the remaining documents as a development set.
They preprocess text like this :
All digits were replaced with the character ’0’. Any words that occurred only once in the training data were replaced by the generic OOV token for word embeddings, but were still used in the character-level components.
The conclusion is :
Developments in neural network research allow for model architectures that work well on a wide range of sequence labeling datasets without requiring hand-crafted data. While word-level representation learning is a powerful tool for automatically discovering useful features, these models still come with certain weaknesses – rare words have low-quality representations, previously unseen words cannot be modeled at all, and morpheme-level information is not shared with the whole vocabulary. So they used character embedding with attention mechanism to overcome those problems.
The paper: Attending to Characters in Neural Sequence Labeling Models (Rei et al., 2016 COLING)