This is a brief summary of paper for me to study and arrange for Boosting Named Entity Recognition with Neural Character Embeddings (Santos and Guimarães., NEWS-WS 2015) I read and studied.
This paper is a research ralted to NER tagging and focus on not using the handcrafted fetaures and the output of other NLP tasks such as part-of-speech tagging and text chuncking.
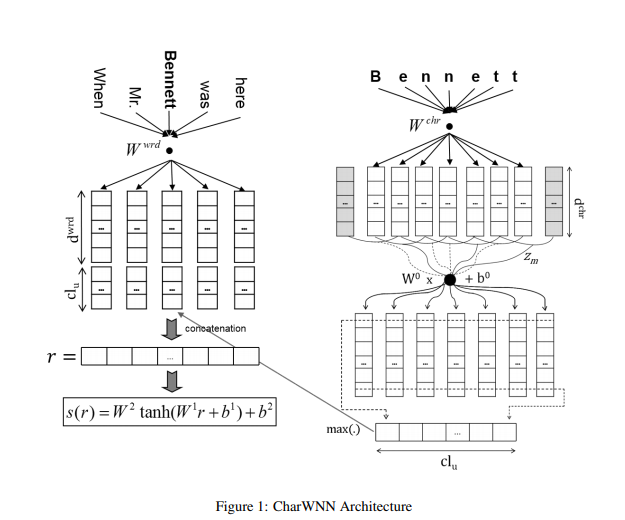
Ther model jointly trained word and character embedding to boost the performance of NER task in Portuguese and Spanish.
representing character embedding in a word, they use covoutional neural network with max operation to generate a fix-size vector.
And then they have an assumption that in sequential classification tag of word mainly depends on its neghboring words.
So they joinlty concatenate word and character embedding corresponding to each word in a window which is hyper-parameter as follows:
They use a tag style called IOB2 where: O, means that the word is not a NE; B-X is used for the leftmost word of a NE type X; and I-X means that the word is inside of a NE type X. The IOB2 tagging style is illustrated in the following example.

The paper: Boosting Named Entity Recognition with Neural Character Embeddings (Santos and Guimarães., NEWS workshop 2015)