This is a brief summary of paper for me to study and arrange for Multi-prototype Chinese Character Embedding (Lu et al. LREC 2016) I read and studied.
This paper is a research ralted to character embedding
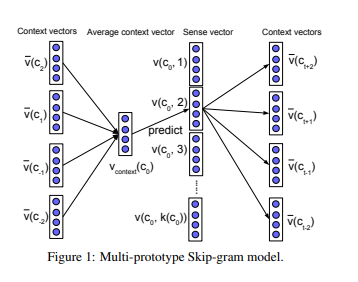
They designed the model to train character vector based on skip-gram model with word as input. there are a reason for their to suggest multi-prototype character embedidng.
The reason is that Characters are highly polysemous in forming words.
They make three significant changes to MSSG for the character embedding task.
First, they predict the sense of the current character given the context directly by using a neural model, rather than by finding the cluster center which is closed to average context vector.
Second, characters are highly order-sensitive in forming words, they add position into the context by combining a character with its position, so each character in each position (relative to the current character position) has a embedding.
This results in a position-sensitive variation of the Skipgram model.
In addition, the number of senses per character is induced from a lexicon rather than automatically.
Their model is as follows: