This is a brief summary of paper for me to study and organize it, From word embeddings to document distances (Kusner et al., ICML 2015) I read and studied.
WMD use word embeddings to calculate the distance so that it can calculate even though there is no common word. The assumption is that similar words should have similar vectors.

First of all, lower case and removing stopwords is an essential step to reduce complexity and preventing misleading.
Sentence 1: obama speaks media illinois
Sentence 2: president greets press chicago
Retrieve vectors from any pre-trained word embeddings models. It can be GloVe, word2vec, fasttext or custom vectors. After that it using normalized bag-of-words (nBOW) to represent the weight or importance. It assumes that higher frequency implies that it is more important.
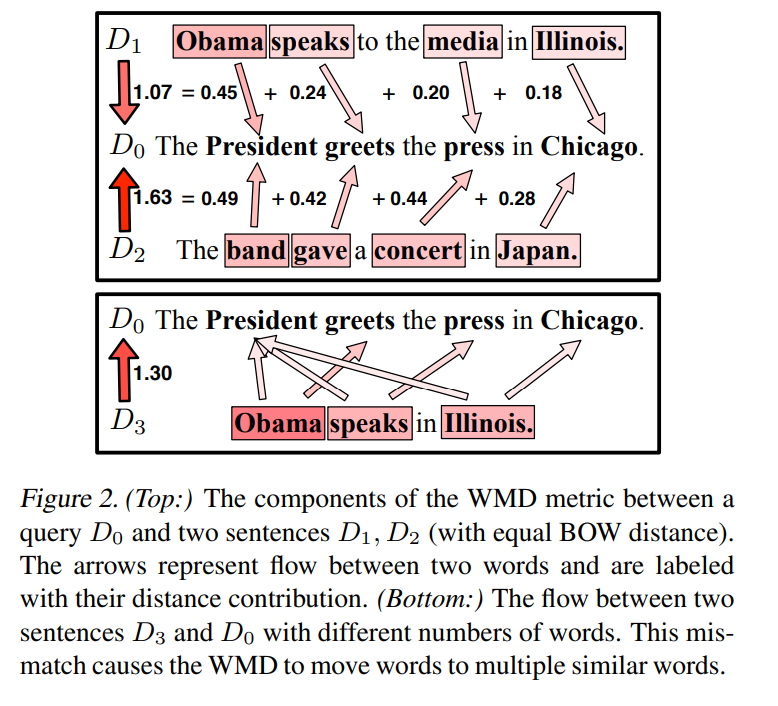
Strengths of WMD:
- Hyperparameter-free
- Straight-forward to understand and use, highly interpretable
- leads to unprecedented low k-nearest neighbor document classification error rates
Reference
- Paper
- How to use html for alert
- References
- Word Embedding to Document distances at slideshare
- From Word Embeddings To Document Distances pdf
- Earth mover’s distance on towards data science
- Paper: The Earth Mover’s Distance as a Metric for Image Retrieval. Rubner et al. 2000 in International journal of computer vision
- The Earth Mover’s Distance as a Metric for Image Retrieval. Rubner et al. 2000
- The Earth Mover’s Distance
- Finding similar documents with Word2Vec and WMD
- Navigating themes in restaurant reviews with Word Mover’s Distance
- A Word is Worth a Thousand Vectors
- Word Distance between Word Embeddings on towards data science
- Word Mover’s Distance as a Linear Programming Problem on Medium