This is a brief summary of paper for me to study and organize it, Improving Word Representations via Global Context and Multiple Word Prototypes (Huang et al., ACL 2012) I read and studied.
They propose new language model using both local and global context.
Also, They release the new dataset for simlilarity on a pair of words in sentential context.
The new dataset included pairs of the homonymous and polysemous words.
When they used the global context, they used tf-idf as weighting function to generate the context vector.
The following figure indicates their model architecture.
Besides global context, They used multi-prototypes to represent the word vector.
In other words, The existing distributed representation of words is problematic with single prototype representaiton.
If words is represented as single prototype, the polysemous and homonymous words is represented as the same vector.
It cannont represent any one of the meanings well as it is influenced by all meaning s of the word.
So, they used multi-prototype approach for vector space model, which uses multiple representations to capture different senses and usages of a word.
In order for them to learn the multi-prototype approach, they use weighted average of context words’ vectors.
They alos used idf-weighting as weighting functions for context vector.
Finally, for multi-prototype approach, each occurence in the corpus is re-labeled to its associated cluster and is used to train the word representation for that cluster.
The following is the architecture figure using global context from Improving Word Representations via Global Context and Multiple Word Prototypes. Huang et al. ACL 2012.
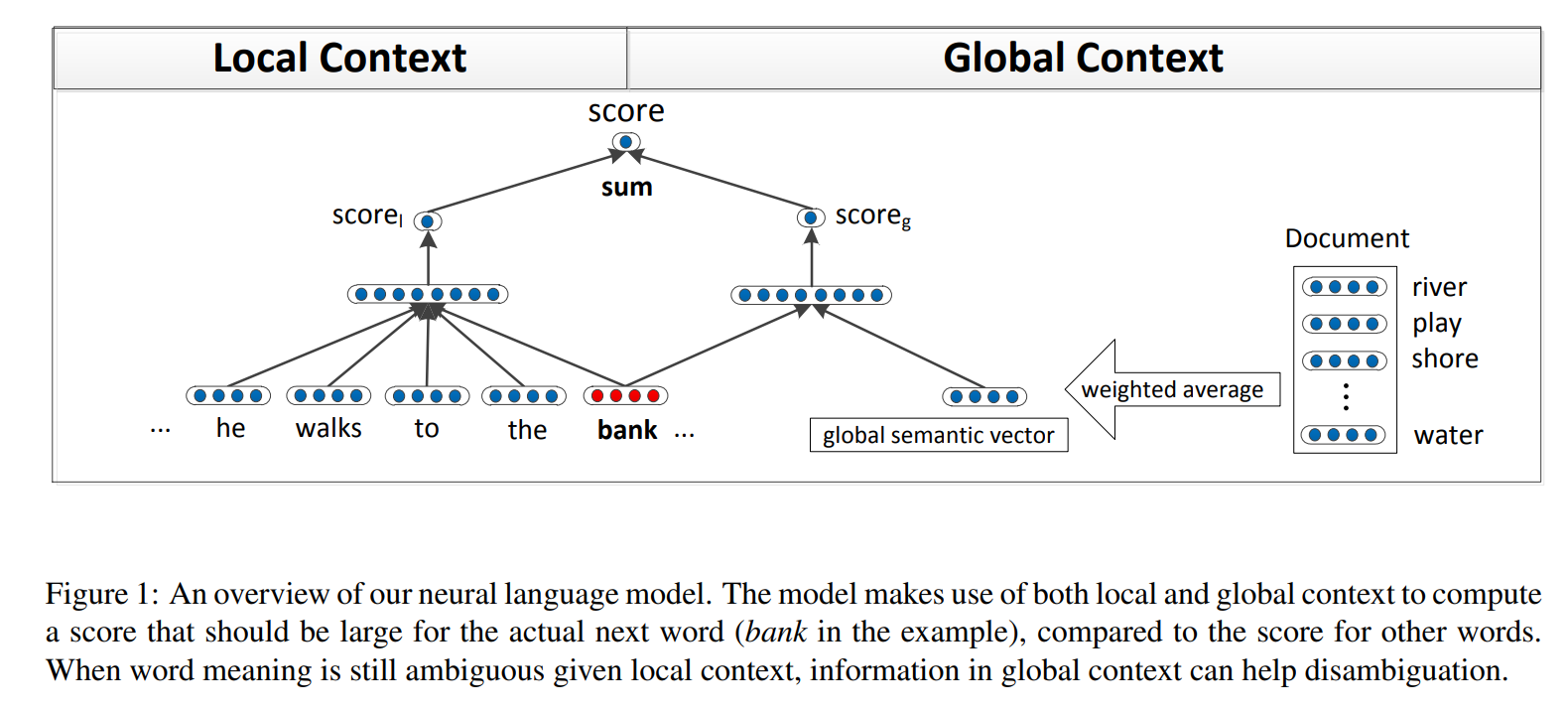
The paper: Improving Word Representations via Global Context and Multiple Word Prototypes (Huang et al., ACL 2012)
Reference
- Paper
- How to use html for alert
- For your information
- ICML 2008: A unified architecture for natural language processing: deep neural networks with multitask learning. Collobert and Weston. ICML 2008.
- EMNLP 2010: A Mixture Model with Sharing for Lexical Semantics. Reisinger and Mooney. EMNLP 2010
- NAACL 2010: Multi-Prototype Vector-Space Models of Word Meaning. Reisinger and Mooney. NAACL 2010