This is a brief summary of paper for me to study and organize it, GLUE- A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding (Wang et al., arXiv 2019) I read and studied.
This paper show a platform for Natural Language understaing tasks as follows:

If you want to submission the platform to test your model across a variety of tasks for NLU.
Visit GLUE benchmark site.
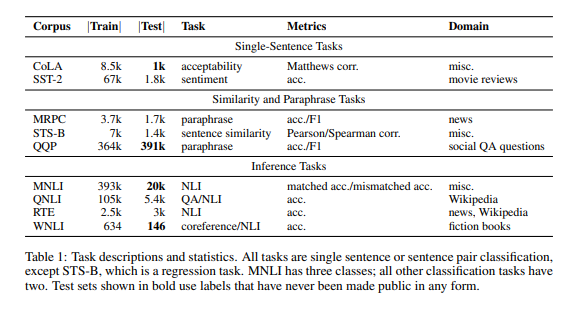
They provide each 9 bechmark sets about NLU tasks.
To recap, the set is composed of the following:
Note(Abstract):
For natural language understanding (NLU) technology to be maximally useful, it must be able to process language in a way that is not exclusive to a single task, genre, or dataset. In pursuit of this objective, they introduce the General Language Understanding Evaluation (GLUE) benchmark, a collection of tools for evaluating the performance of models across a diverse set of existing NLU tasks. By including tasks with limited training data, GLUE is designed to favor and encourage models that share general linguistic knowledge across tasks. GLUE also includes a hand-crafted diagnostic test suite that enables detailed linguistic analysis of models. They evaluate baselines based on current methods for transfer and representation learning and find that multi-task training on all tasks performs better than training a separate model per task. However, the low absolute performance of our best model indicates the need for improved general NLU systems.
Download URL:
The paper: GLUE- A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding (Wang et al., EMNLP 2018)
The paper: GLUE- A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding (Wang et al., EMNLP 2018)
Reference
- Paper
- How to use html for alert
- For your information