This is a brief summary of paper for me to study and organize it, Deep Contextualized Word Representations (Peters et al., NAACL 2018) I read and studied.
Their archtecture could be shown as following:
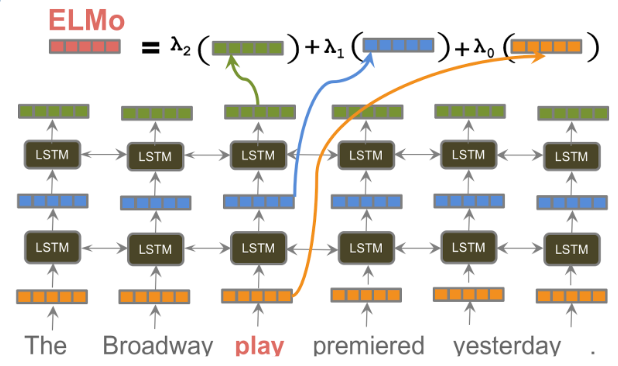
Pretrain deep bidirectional LM, extract contextual word vectors as learned linear combination of hidden states
For detail of therir method, If you want to require it, visit the videos below.
Note:
They introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Their word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pretrained on a large text corpus. They show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. They also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
ELMo Youtube & language model youtube
Reference
- Paper
- How to use html for alert
- For your information