This is a brief summary of paper for me to study and organize it, Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank (Socher et al., EMNLP 2013) I read and studied.
This paper focused on the compositionalty of semantic vector space based on a well-structed tree.
They suggest model and how to compositionality of sentimental data as followings:
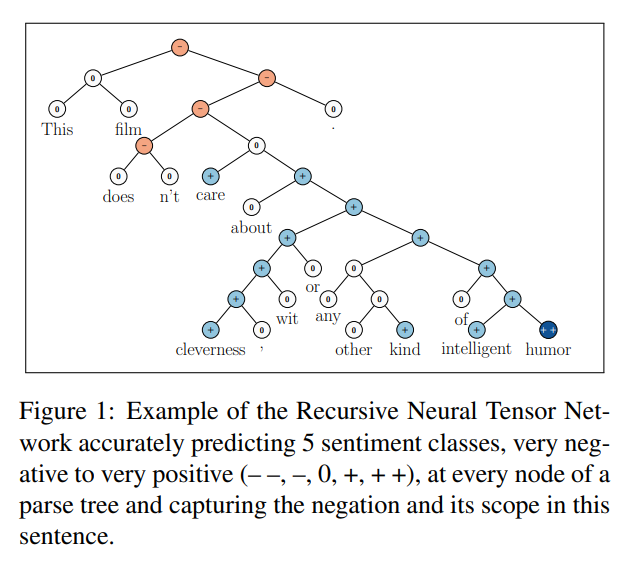
They provide a new model to embed the compositionality of new dataset called the Stanford Sentiment Treebank
They called the model RNTN (recursive neural tensor network).
They said in recent years,
sentiment accuracies even for binary positive/negative classification for single sentences has not exceeded 80% for several years. For the mor difficult multiclass case including a neutral class, accuary is oftne below 60% for short meassages on Twitter.
From a linguistic or conginitive standpoint, ignoring word order in the treatment of a semantic task is no plausible.
Also they found
some from labeling sentences based on reader’s perception is that many of them could be considered neutral. Besides they found that stronger sentiment often builds up in longer phrases and majority of the shorter phrases are neutral. Another observation is that most of annotators moved slider to on e fo the five position: negative, somewhat negative, neutral, somewhat positive, or positive. the extreme values were rarely used and the slider was not often left in between the ticks.
They used softmax as classifier on each node as followings:
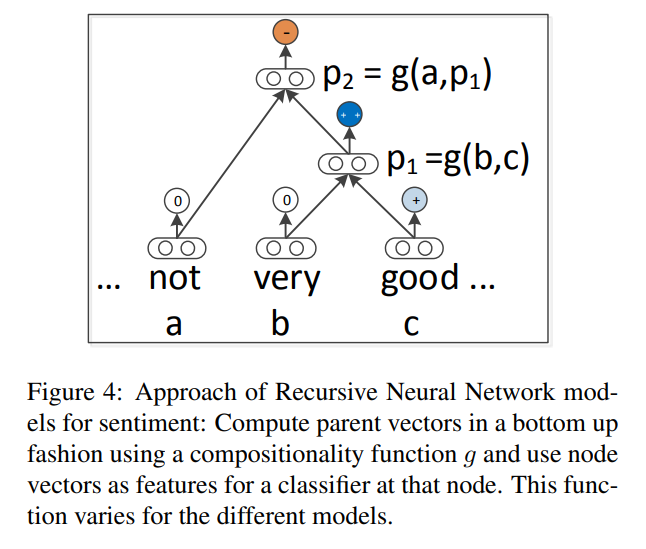
As you can see the figure above, they use word vectors immediately as parameters to optimize and as feature input to a softmax classifier.
Let’s walk through recursive neural network ahead of getting to their model RNTN.
The simplest member of the family of recursive neural networks is the standard recursive neural network
First, it is determined which parent already has all its children computed. In the above exmple figure, \(p_1\) has its two children’s vectors since both are words. the standard recursive neural network(RNN) uses the following equations to compute the parent node vectors:
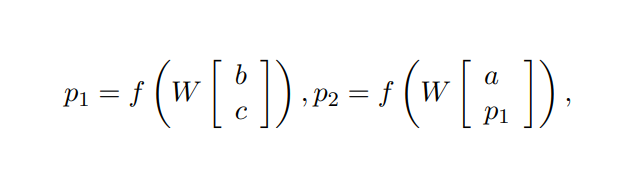
Where $f=tanh$ is a standard element-wise nonlinearity. The dimensionality of parent node vectors is the same from that of childrens for recursive composition.
The second member of RNNs is Matrix-Vector RNN (MV-RNN) that is linguistically motivated in that most of the parameters are associated with words and each composition function that computes vectors for longer phrases depends on the actual words being combined.
For this model, each n-gram is represented as al ist of (vector, matrix) paris, together with the parse tree. For the tree with (vector, matrix) nodes:

Where \(W_M \in \mathbb R^{d \times 2d}\) and the result is againa \(d \times d \) matrix
Finally, Their resulting model to resolve the one problem with the MV-RNN is RNTN(recursive Neural Tensor Netowrk) as followings:
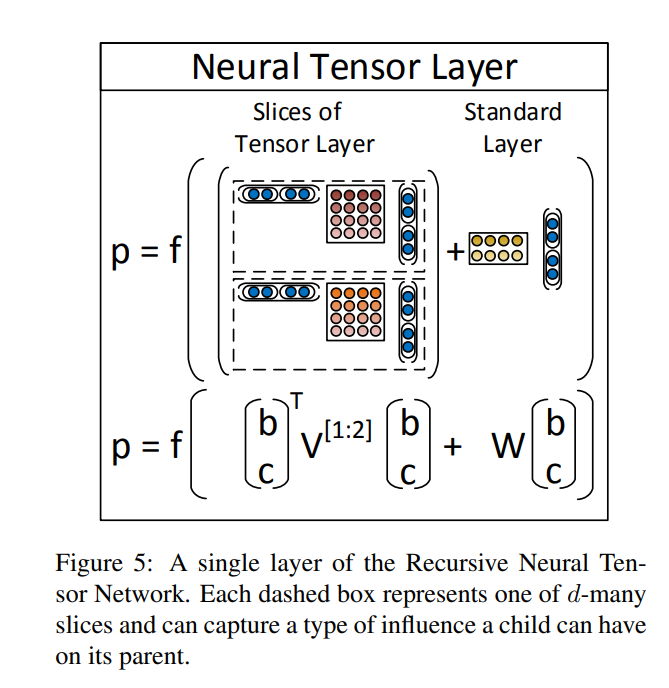
The paper: Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank (Socher et al., EMNLP 2013)
Reference
- Paper
- How to use html for alert
- For your information