This posting is summary for my study about the paper, “GloVe: Global Vectors for Word Representation (Pennington et al., EMLNP 2014)”
There are two methodologies for distributional word representations.
one is to be learned from count-based method like latent semantic anlaysis-LSA(Deer-wester et al., 1990) and hyperspace analogue to Language-HAL(Lund and Burgess, 1996).
-
based on frequencies of terms.
1) In LSA, matrix of term-document type like bag-of-words matrix: rows correspond to words or terms, and the columns correspond to different documents in corpus.
2) In HAL, matrix of term-term type like co-occurence matrix: rows correspond to words, and the columns correspond to the entries which is the number of times a given word occurs in the context of another given word.
- In particular, co-occurence matrix could be transformed to an entropy- or correlations-based normalization.
3) PPMI(Bullinaria and Levy 2007), square root type HPCA-Hellinger PCA(Lebret and Collobert, 2014) and so on.
The other is prediction-based method like Word2Vec(Mikolov et al., 2013), vLBL and ivLBL(Mnih and Kavukcuoglu 2013), Bengio et al.(2003), Collobert and Weston(2008), Collobert et al.(2011).
All the methods above could be separated into the Matrix Factorization Method(i.e. NMF:Non-negative Factorization) and the Shallow Window-Based Methods.
GloVe
GloVe paper said the statistics of word occurrence in a corpus is the primary source of information available to al unsupervised methods for learning word representation.
So, GloVe utilized are the matrix word-word co-coccurence with context window size.
Above all, Let’s see notation for equation of GloVe.
Let the matrix of word-word co-occurrence counts be denoted by X, whose entries \(X_{ij}\) tabulate the number of times word j occurs in the context of word i.
Let \( X_{i}=\sum_{k}X_{ik} \) be the number of times any word appears in the context of word i.
Finally, let \( P_{ij}=P(j|i)=X_{ij}/X_{i} \) be the probability that word j appear in the context of word i.
The following would explain how to correlate the ratio of co-occurrence of target words for information to embed the distinction of words.

GloVe is log-bilinear regression model and then the cost function is the same from the following
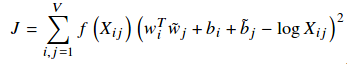
As you can see above, \( f(X_{ij}) \) is weighting function. The weighting function should be obey the following properties:
-
f(X) should be non-decreasing so that rare co-occurences are not overweighted.
-
f(X) should be relatively small for large value of X, so that frequent co-occurences are not overweighted.
f(X) function below was used in the GloVe paper
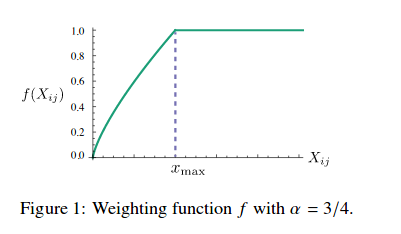
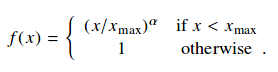
As you can see the cost function, GloVe calculates co-occurence matrix to update
\( W_{i} \), word vector and \( W_{j} \), context word vector.
So, if the corpus is changed, you need to update the co-occurence matrix.
The cost function calculates the least square of \(W_{i}^T\)*\(W_{j}\) - \(log(X_{ij})\)
\(X_{ij}\) is the number of times word k appears in the context of word i.
The paper: GloVe:Global Vectors for Word Representation
Reference
- Paper
- How to use html for alert
- online Learning
-
Online Learning on Linkedin Slide
- I think the aobve links I read a little is very interesting. later on I would read both of them and papers related to it.
-
word embeddings in 2017: Trends and Future directions on Sebastian Ruder blog
- A survey of cross-lingual word embedding models on Sebastian Ruder blog