After I read the paper, Efficient Estimation of Word Representations in Vector Space titled.
I think I need to make the test set of syntactic and semantic qeustion into another language.
In particular, I want to translate the test set into Korean language. Becuase I am researcher of Korean language NLP.
But If you guys use this respository I store with work I did. you can translate the test set into another language including language set the module, googletrans is providing.
First, git clone the Hyunyoung2 Korean test set v1
and then run Download_test_set.sh under Efficient_Estimation_of_Word_Representations_in_Vector_Space dir in English dir.
you will get the text file, word-test.v1.txt like this:
./Download_test_set.sh
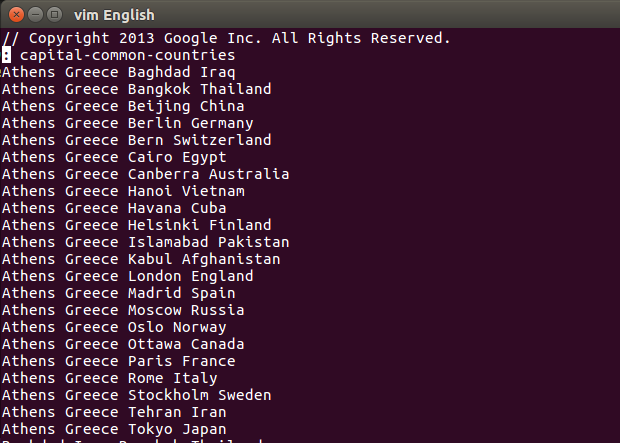
Second, run the python script, google_trans.py.
before running google_trans.py, After enter the paper directory, run the script as follows:
python3 google_trans.py
The directory is Efficient_Estimation_of_Word_Representations_in_Vector_Space.
In my case, I normally use python3, so I run the python script above with python3.
If you want to see the code, You could check my repository
just I did programming on google_trans.py, I verified the python script with pylint
The following is just information about using pylint.
- with pip3 install pylint, i.e. python package for python3

- with apt-get install pylint i.e. ubuntu package
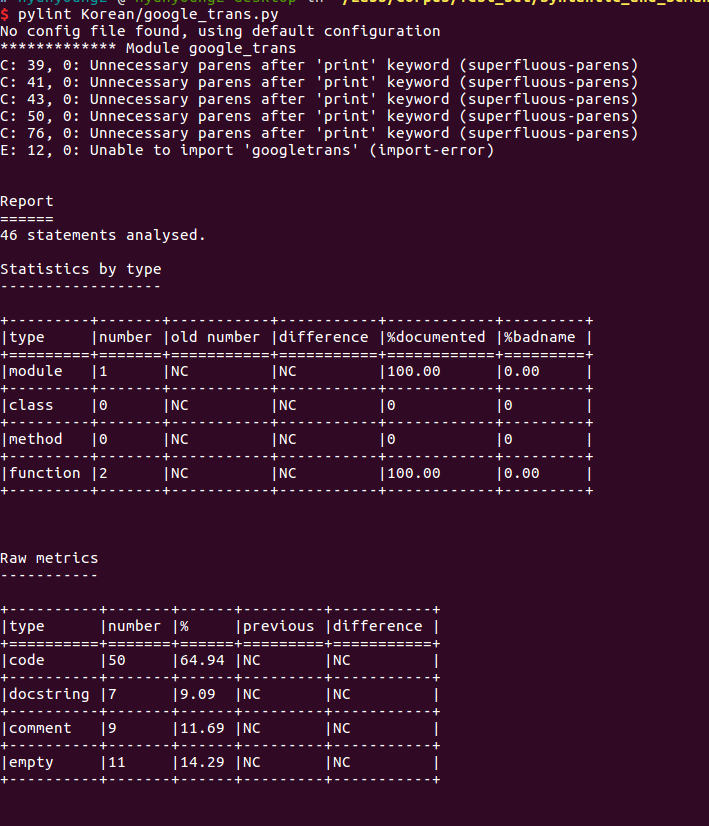
Finally, after running the python script, google_trans.py, the result is as follows:
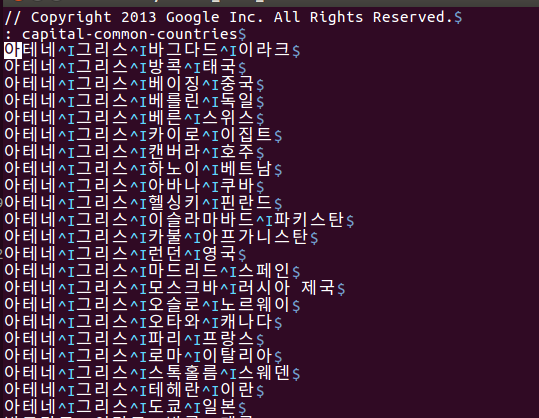
After I finished this job, I think that has error on syntactic qeustions, Later I have to fix this data of syntactic question to Korean Language.
Another problem is unigram in english is tuned into bigram or trigram in Korean after tranlating as follows:
Georgetown -> 조지 타운
Later I will resolve it.