This is a brief summary of paper for me to study and simply arrange it, From Characters to Words to in Between: Do We Capture Morphology? (Vania and Lopez., ACL 2017) I read and studied.
They investigated the composotion function on word using character, morphem, and word with language model task as follows:
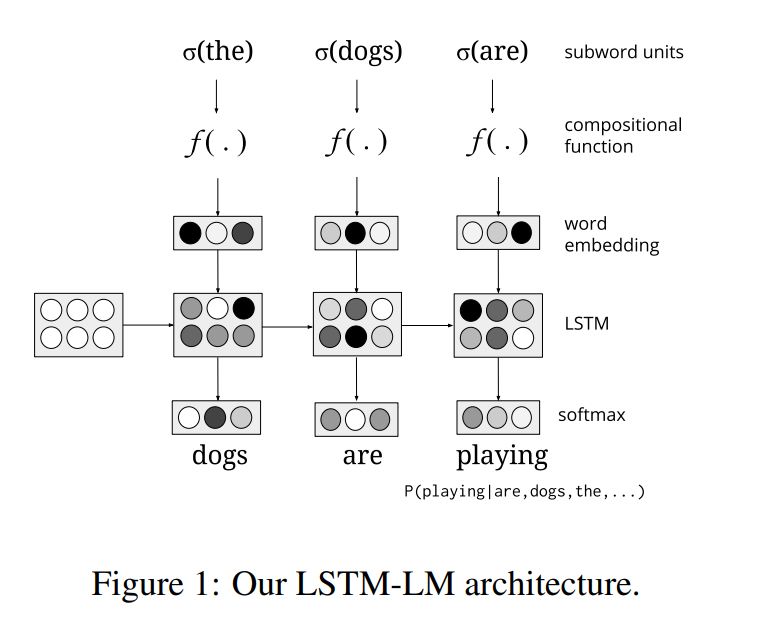
They found out the Bi-LSTM compostion function is usually better than CNN and add in different languages.
If tested with morphological analyzer, character embedding shows better performance on language model task rather than morpheme representation.
But, on arcle experiment the true morphological analysis is better than character representation in Czech and Russian.
Note(Abstract):
Words can be represented by composing the representations of subword units such as word segments, characters, and/or character n-grams. While such representations are effective and may capture the morphological regularities of words, they have not been systematically compared, and it is not understood how they interact with different morphological typologies. On a language modeling task, we present experiments that systematically vary (1) the basic unit of representation, (2) the composition of these representations, and (3) the morphological typology of the language modeled. Their results extend previous findings that character representations are effective across typologies, and they find that a previously unstudied combination of character trigram representations composed with bi-LSTMs outperforms most others. But they also find room for improvement: none of the character-level models match the predictive accuracy of a model with access to true morphological analyses, even when learned from an order of magnitude more data.
Download URL:
The paper: From Characters to Words to in Between: Do We Capture Morphology?. Vania and Lopez. 2017 ACL
The paper: From Characters to Words to in Between: Do We Capture Morphology?. Vania and Lopez. 2017 ACL
Reference
- Paper
- How to use html for alert
- For your information