This is a brief summary of paper for me to study and organize it, QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension (Yu et al., ICLR 2018) I read and studied.
This paper proposed data augmentation technique and model, which execulsively used convolution and self-attention, for question answering task.
Let’s first start formulate the reading comprehension task:
Machine Reading Comprehension Formulation: The The reading comprehension task considered in this paper, is defined as follows. Given a context paragraph with n words C = {\(c_1, c_2, …, c_n)\} and the query sentence with m words Q = {\(q_1, q_2, …, q_m)\}, output a span S = {\(c_i, c_{i+1}, …, c_{i+j})\} from the original paragraph C. In the following, we will use x to denote both the original word and its embedded vector, for any x ∈ C, Q.
The resulting representation from their model is encoded again with our recurrency-free encoder before finally decoding to the probability of each position being the start or end of the answer span as following:
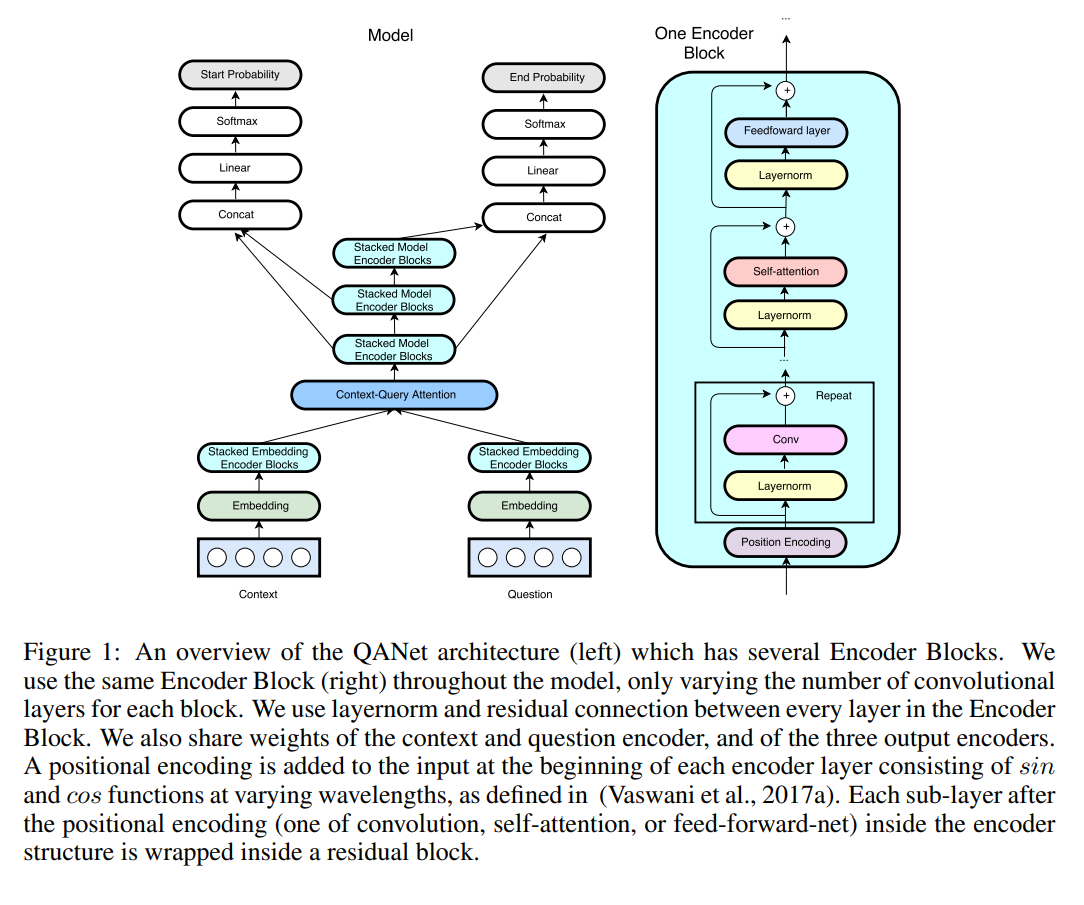
They argued that the recurrency-free model make their model faster than The RNN counterparts.
For the detailed model components, refer to the paper, QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension (Yu et al., ICLR 2018)
For data augmentation, they used back-translation techique for machine reading comprehension task that they are interested in.
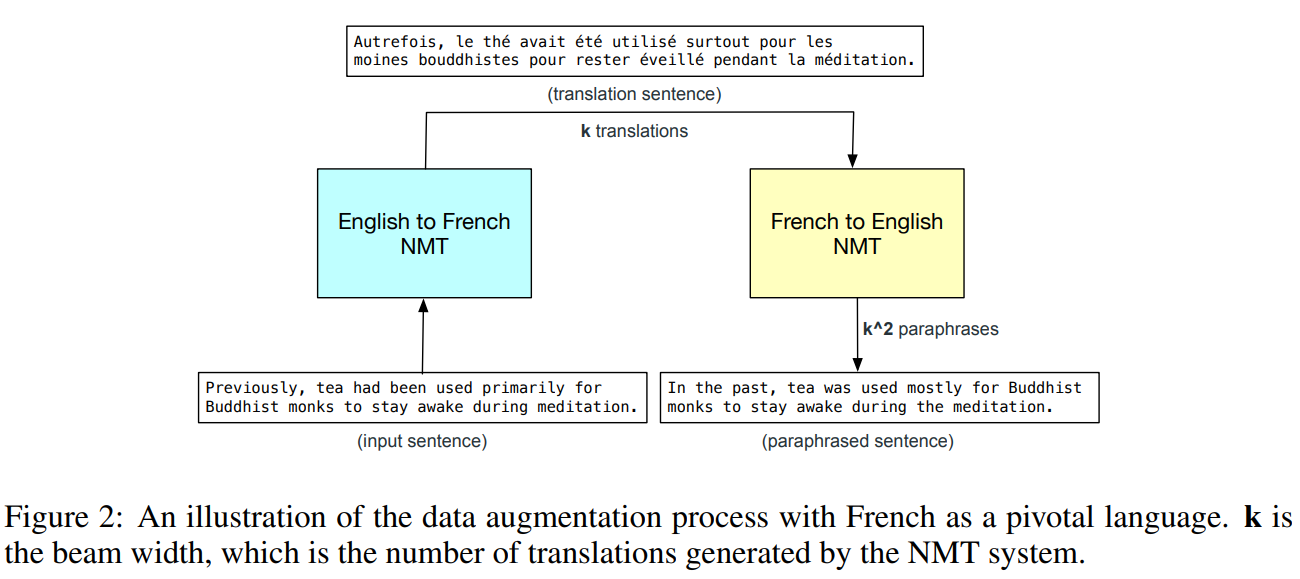
The paper: QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension (Yu et al., ICLR 2018)