This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Beyond the Next Token: Towards Prompt-Robust Zero-Shot Classification via Efficient Multi-Token Prediction (Qian et al. arXiv 2025), that I read and studied.
For detailed experiment and explanation, refer to the paper, titled Beyond the Next Token: Towards Prompt-Robust Zero-Shot Classification via Efficient Multi-Token Prediction (Qian et al. arXiv 2025)
Note(Abstract):
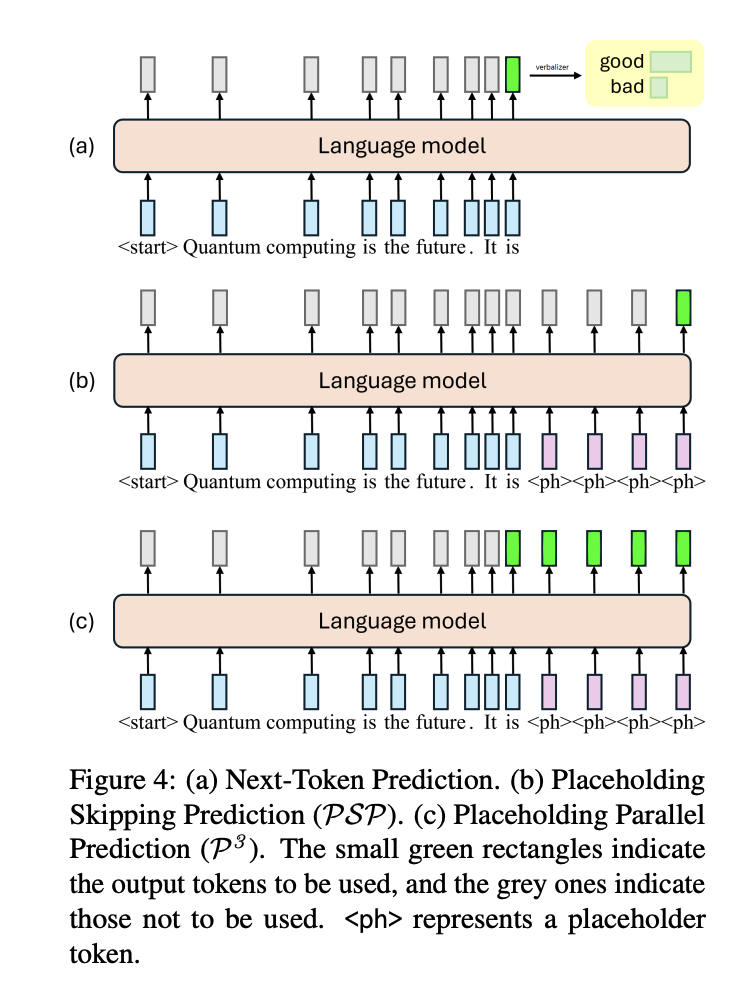
Zero-shot text classification typically relies on prompt engineering, but the inherent prompt brittleness of large language models undermines its reliability. Minor changes in prompt can cause significant discrepancies in model performance. We attribute this prompt brittleness largely to the narrow focus on nexttoken probabilities in existing methods. To address this, we propose Placeholding Parallel Prediction (P3), a novel approach that predicts token probabilities across multiple positions and simulates comprehensive sampling of generation paths in a single run of a language model. Experiments show improved accuracy and up to 98% reduction in the standard deviation across prompts, boosting robustness. Even without a prompt, P3 maintains comparable performance, reducing the need for prompt engineering.
Reference
- Paper
- For your information
- How to use html for alert
- How to use MathJax