This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled An Image is Worth 16 X 16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al. arXiv 2021), that I read and studied.
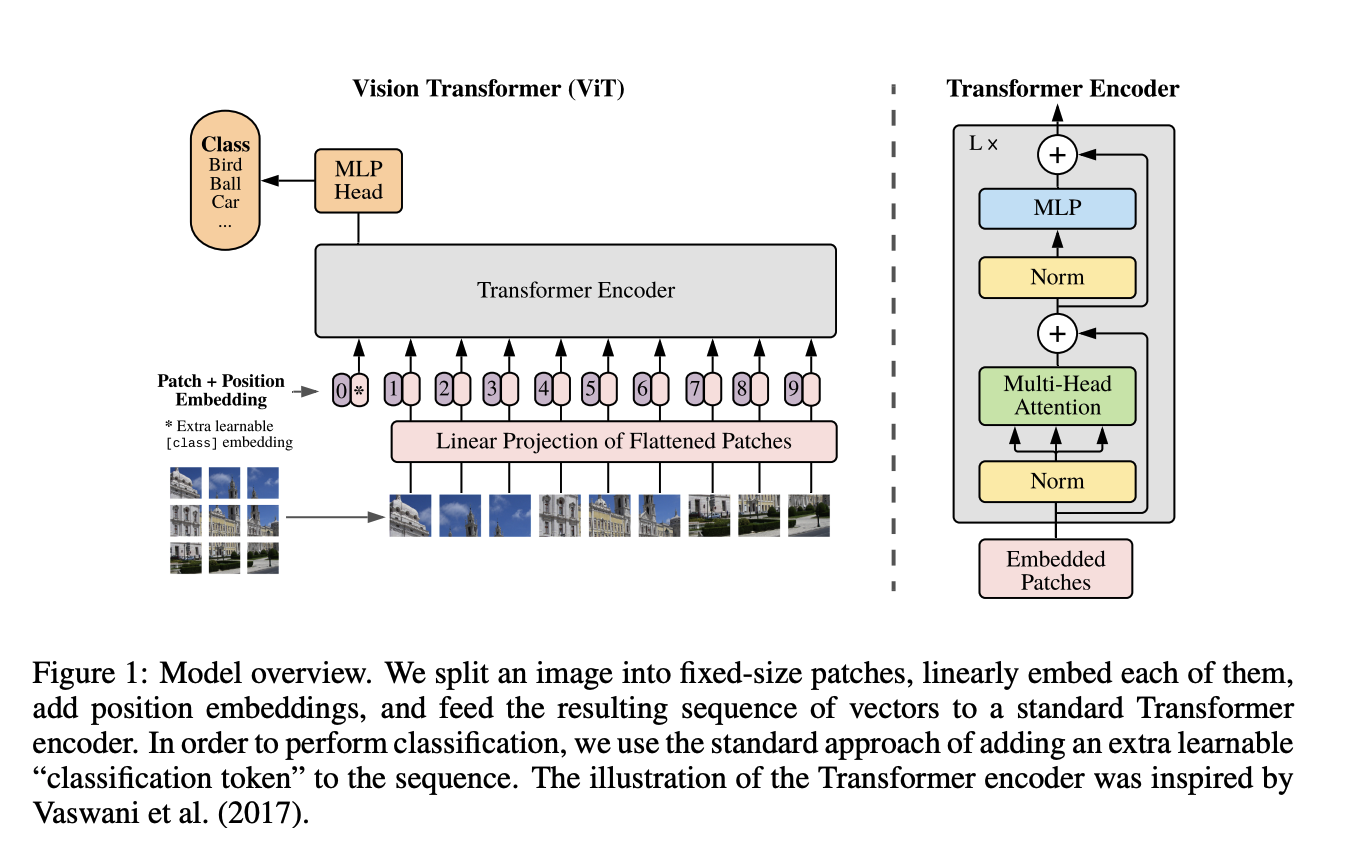
For detailed experiment and explanation, refer to the paper, titled An Image is Worth 16 X 16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al. arXiv 2021)
Note(Abstract):
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Download URL:
The paper: An Image is Worth 16 X 16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al. arXiv 2021)
The paper: An Image is Worth 16 X 16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al. arXiv 2021)
Reference
- Paper
- For your information
- How to use html for alert
- How to use MathJax