This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Visual Instruction Tuning (Liu et al., arXiv 2023), that I read and studied.
The primary goal is to effectively leverage the capabilities of both the pre-trained LLM and visual model. The network archtecture is illustrated in Figure 1.
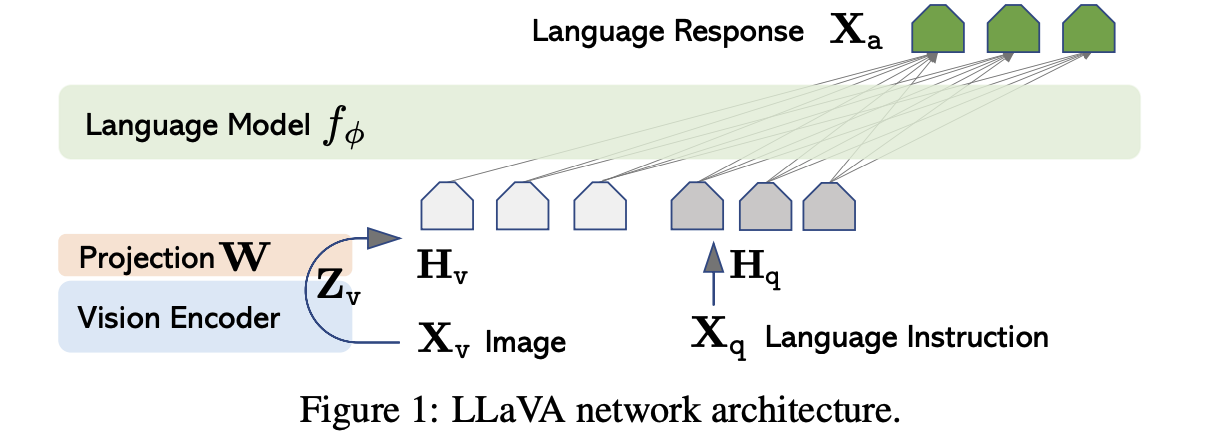
For viaul token \(H_v\), they use linear projection.
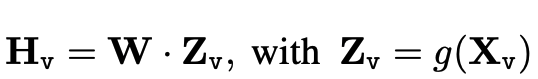
For Instruction \({X^t}_instruction\), it is comprised of the follwoing:
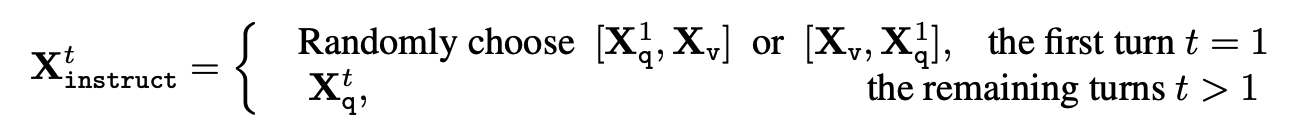
For detailed experiment and explanation, refer to the paper, titled Visual Instruction Tuning (Liu et al., arXiv 2023)
Note(Abstract):
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has been shown to improve zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and an LLM for generalpurpose visual and language understanding. To facilitate future research on visual instruction following, we construct two evaluation benchmarks with diverse and challenging application-oriented tasks. Our experiments show that LLaVA demonstrates impressive multimodal chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions.
Reference
- Paper
- For Your Information
- How to use html for alert
- How to use MathJax