This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Self-Rewarding Language Models (Yuan et al., arXiv 2024), that I read and studied.
They proposed that Self-Rewarding Langauge Models where the language model itself is used via LLM-as-a-Judge prompting to Provided its own rewards during training.
They show that during iterative DPO training that not only does instruction following ability improve, but also the ability to provide high-quality rewards to itself.
Aligning large Language Models (LLMs) using human preference data can vastly improve the instruntion following performance of pretrained models.
The standard approach of Reinforcement Learning from Human Feedback (RLHF) learns a reward model from these humanc preferences.
The reward model is then frozen and used to train the LLM using RL., e.g., via PPO.
So. we instead propose to train a self-improving reward model that, rather than being frozen, is continually updating during LLM alignment, in order to avoid this bottleneck.
The key to such an approch is to develop an agent that possesses all abilities desired during training, rather than separating them out into distinct models such as a reward model and a language models.
For detailed experiment and explanation, refer to the paper, titled Self-Rewarding Language Models (Yuan et al., arXiv 2024)
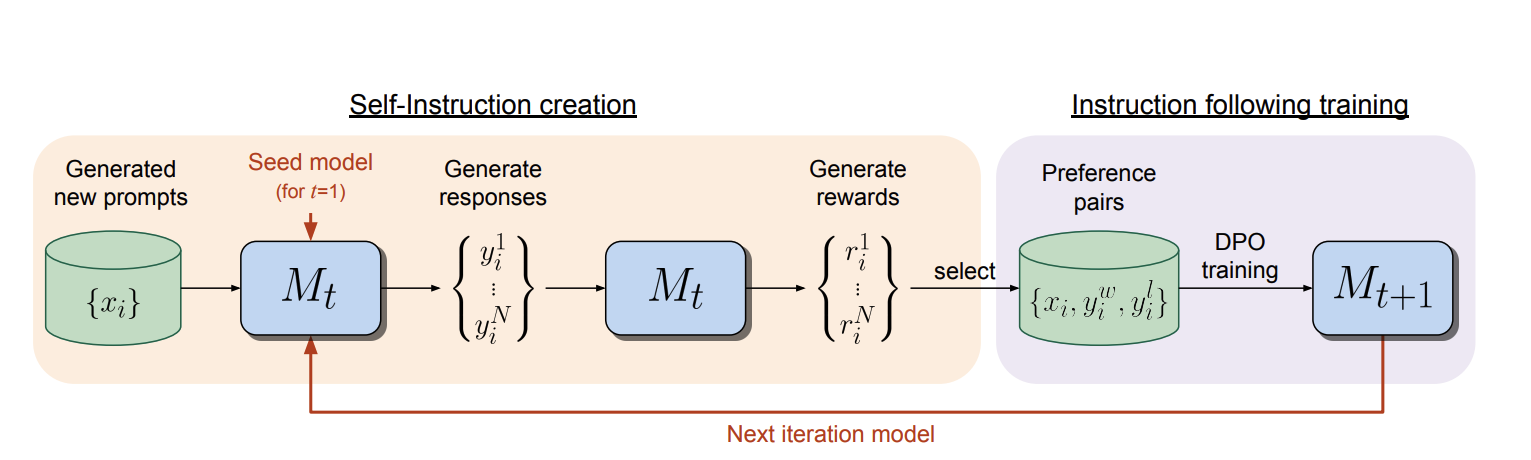
As you can see the Self-Rewarding Language Models above, their self-alignment methods consists of two steps:
(1) Self-instruction creation: newly created prompts are used to generate candiate responses from model $M_{t}$ which also predicts its own rewards via LLM-as-a-Judge prompting.
(2) Intstruction following training: preference pairs are selected from the generated data, which are used for training via DPO, resulting in model $M_{t+1}$.
The whole procedure above can then be iterated resulting in both improved instruction following and reward modeling ability.
Lets’ see their Self-Rewarding Language Models.
Their approach first assumes access to a base pretrained langauge models, an a small amount of human-annotated seed data.
They then build a model that aims to possess two skills simultaneously:
- Instruction following: given a prompt that describes a user request, the ability to generate a high quality, helpful (and harmless) response.
- Sefl-Instruction creation: the ability to generate and evaluate new instruction-following examples to add to its own training set.
These skills are used to that the model can perform self-alignment, i.e., they are the components used to iteratively train itself using AI Feedback (AIF).
Let’s see the detail of self-rewarding LLM.
- Seed instruction following data, called Instruction Fine-Tuning (IFT), which is hunam-authored (instruction prompt, response) general instruction following examples in a SFT manners.
- Seed LLM-as-a-Judge instruction following data which is a seed set of (evaluation instruction prompt, evaluation result response) examples which can also be used for training. The evaluation standard is five additive criteria (relevance, coverage, usefulness, clarity and expertise), covering various aspects of quality that is called Evaluation Fine-Tuning (EFT) data.
-
Self instruction Creation : To self-modify its own trainin set, The following steps is implemented as followings:
3-1. Generate a new prompt $x_{i}$ using few-shot prompting, sampling prompts from the original seed IFT data.
3-2. Generate candidate responses: N diverse candidate response ${y_{1}, … ,y_{N},}$ for the given prompt $x$.
3-3. Evaluate candiate response: the LLM-as-a-Judge ability of our same model to evaluate its own candidate responses with scores from 0 to 5.
-
Instruction following Training: training is initially performed with the seed IFT and EFT data. This is then augmented with an additional data via AI (Self-)Feedback.

-
Overal Self-Alignment Algorithm 5-1. Interative Training : Their overal procedure trains a series of models $M_{1}, M_{2}, M_{3}, …, M_{T}$ where each successive model $t$ uses augmented training data created by the $(t-1)^{th}$ model. 5-2. Model sequence:
$M_0$: Base pretrained LLM with no fine-tuning. $M_1$: Initialized with $M_{0}$, then fine-tuned on the IFT+EFT seed data using SFT. $M_2$: Initialized with $M_{1}$, the trained with AIFT($M_{1}$) data using DPO. $M_3$: Initialized with $M_{2}$, the trained with AIFT($M_{2}$) data using DPO.
For detailed experiment and explanation, refer to the paper, titled Self-Rewarding Language Models (Yuan et al., arXiv 2024)
Reference
- Paper
- HuggingFace
- For your information
- [What Does Learning Rate Warm-up Mean?(https://www.baeldung.com/cs/learning-rate-warm-up)
- Relation Between Learning Rate and Batch Size
- How to use html for alert
- How to use MathJax