This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs (Li et al., NeurIPS 2023), that I read and studied.
They proposed the new type of dataset which is called BIRD (i.e. a BIg bench for laRge-scale Database grounded in text-to-SQL task).
They said the existing dataset, i.e., WikiSQL and Spider, focus on database schema with few rows of database values leaving the gap between academic study and real-world applicationm. To reduce the gap, they present BIRD benchmark.
From the benchmark, they imply external knowledge grounding problem, database value comprehension, in Text2SQL task.
In addition, they tackled the efficiency of SQL generated from Text2SQL model which matter in industries.

The following shows the overall process of the BIRD Annotation Workflow
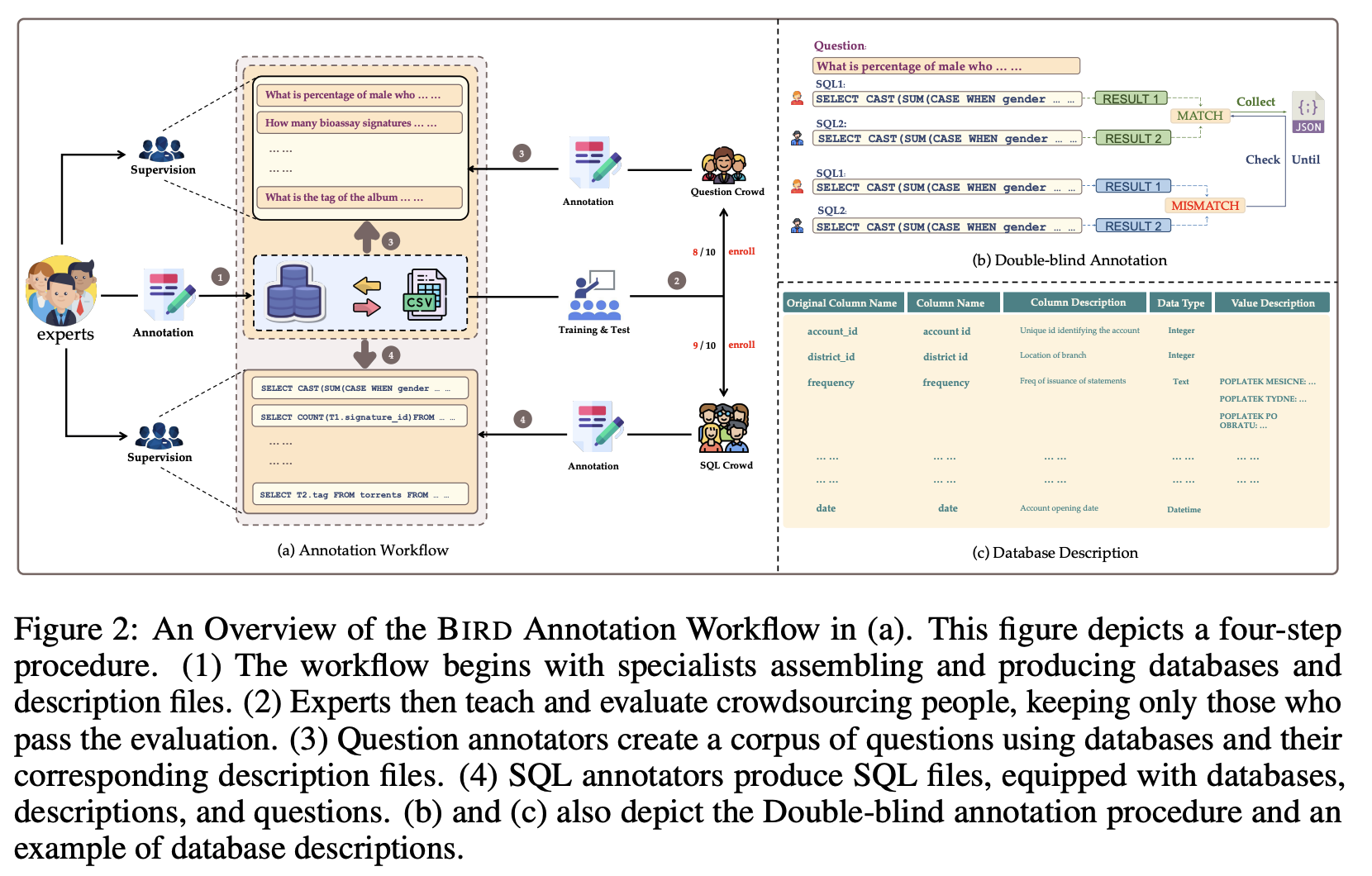
For detailed experiment and explanation, refer to the paper, titled Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs (Li et al., NeurIPS 2023)
Reference
- Paper
- Leaderboard & Github
- How to use html for alert
- How to use MathJax