This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled LLaMa2: Open Foundation and Fine-Tuned Chat Models (Touvron et al., arXiv 2023), that I read and studied.
In the paper, they share novel observations during the development of LLAMA2 and LLAMA2-Chat such as the emergence of tool usage and temporal orgainzation of knowledge.
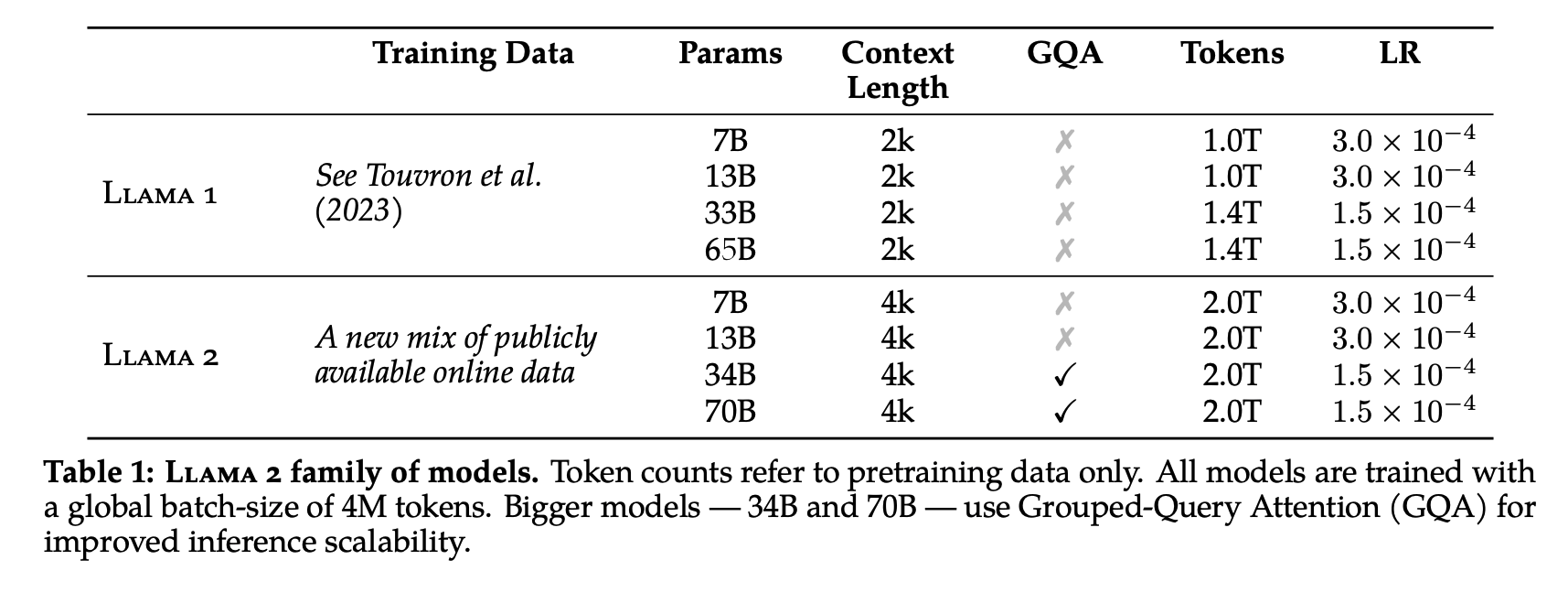
The difference between LLAMA1 and LLAMA2 is the grouped-query attention introduction, context length, and token size of train corpus.
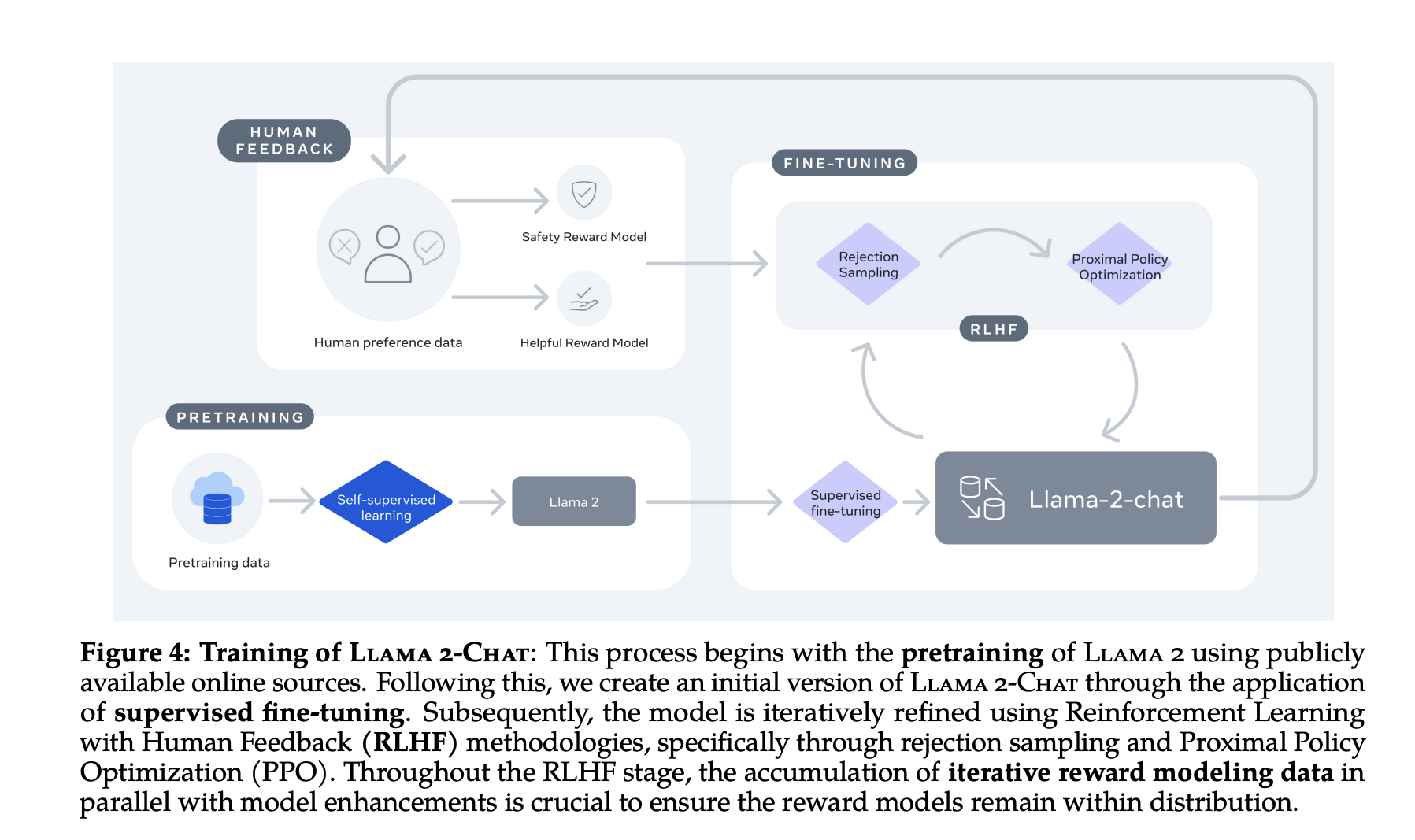
They also share new tochinique, Ghost attention which helps control dialogue flow over multiple turns.
They learn preferecne of human with RLHF with binary ranking loss + margin for helpfulness and satety.
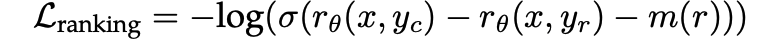
For detailed experiment and explanation, refer to the paper, titled LLaMa2: Open Foundation and Fine-Tuned Chat Models (Touvron et al., arXiv 2023)
The paper: LLaMa2: Open Foundation and Fine-Tuned Chat Models (Touvron et al., arXiv 2023)
Reference
- Paper
- How to use html for alert
- How to use MathJax