This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models (Ni et al., ACL 2022), that I read and studied.
They proposed how to represent sentence embedding with T5 model known as pretrained model as text-to-text format.
They call the proposed method ST5 which stands for Sentence-T5.
As you can see figure below, they empirically tried to compare Sentence-T5 with BERT-based sentence embedding on sentence task
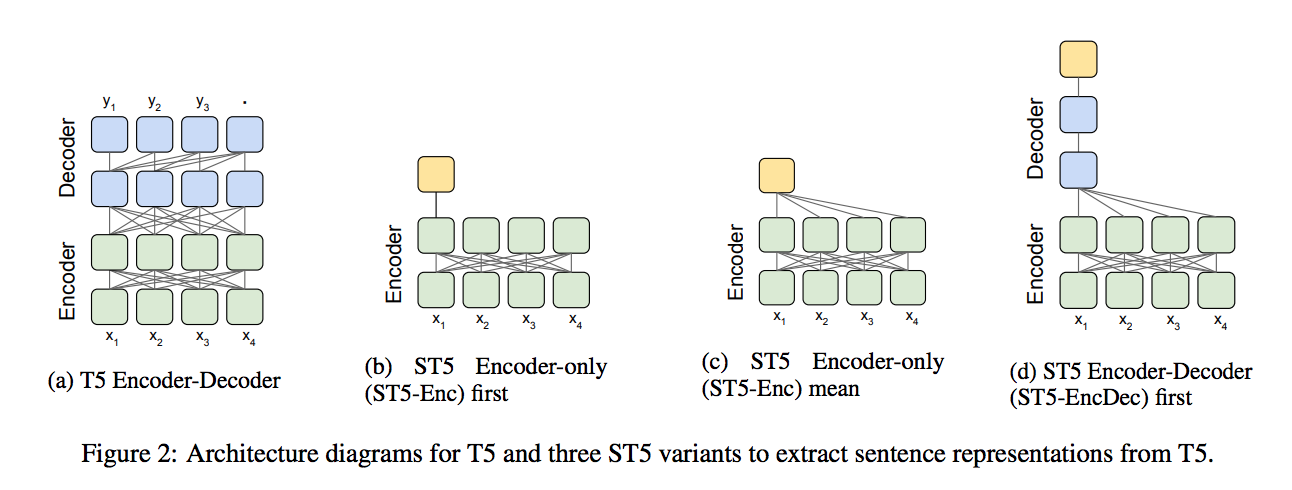
They proposed two structures to represent sentence embedding, ST5 Encoder-only model and ST5 EncDec model with T5 model.
ST5 Encoder-only utilizes the encoder part from encoder-decoder of T5 model, the ST5 EncDec utilizes encoder-decoder structure of T5 model.
To sum up, ST5 Encoder-only with mean pooling and first token or ST5 EncDec with first token on decoder is used for sentence embedding.
You can see the detailed empirical analysis and experiemtn in the paper, titled Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models (Ni et al., ACL 2022)
For detailed experiment and explanation, refer to the paper, titled Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models (Ni et al., ACL 2022)
The paper: Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models (Ni et al., ACL 2022)
Reference
- Paper
- How to use html for alert
- How to use MathJax