This is a brief summary of paper for me to study and organize it, Neural Attention Models for Sequence Classification: Analysis and Application to Key Term Extraction and Dialogue Act Detection (Shen and Lee, arXiv 2016) that I read and studied.
They propose sequence classificaiton model conbining long short-term memory(LSTM) with attention mechanism like the following figure:
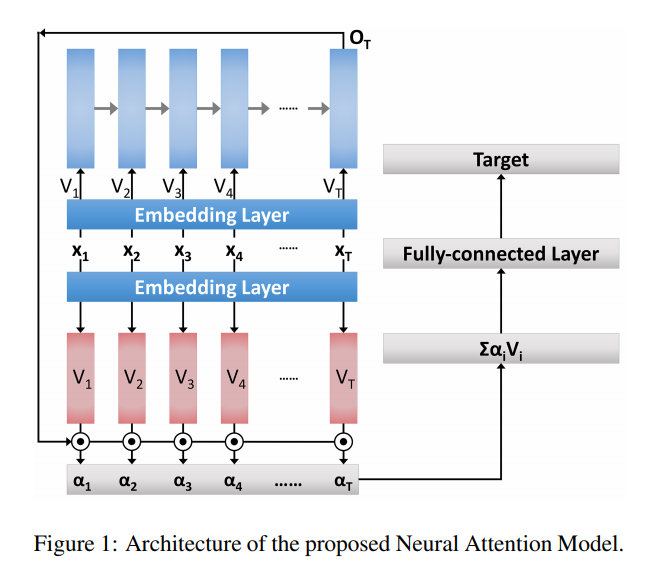
As you can see Figure 1, first they summarize a input sequence as a fixed-size vector which is output vector \(O_T\) of LSTM and then use the summarized vector \(O_T\) and input seqeunce vector \(V = (V_1, V_2, …, V_T)\) for attention mechanism.
For all the parameters in embedding layer, they are shared in input of LSTM and attention mechanism.
In the figure 1, embedding layer denotes a linear transforamtion matrix.
Before digging into attention mechanism, Let’s see several annotations.
-
The set \(x = (x_1, x_2, …, x_T)\) denotes input sequence, where T is the sequence length. Each element in \(x\) represent a fixed-length featur vector.
-
The word embedding set \(V = (V_1, V_2, …, V_T)\) indicates input seqeunce vectors.
-
\(O_T\) denote output vector which can be regarded as the summariess of the preceding feature vector.
-
The set \(e = (e_1, e_2, …, e_T)\) denotes a list of score.
-
The set \( \alpha = (\alpha_1, \alpha_2, …, \alpha_n)\) denotes a list of attention weight.
When the calculate score between output vector and input sequence vector, they use cosine similarity.
\[e_i = O_T \odot V_i\]Where \(\odot\) denotes cosine similarity between the summarizaed output vector \(O_T\) and input vector \(V_i\)
They also normalized the score for attention mechanism in two ways.
For sharpening, it use the softmax to normalizae socres.
\[\alpha_i = \frac{exp(e_i)}{\sum_{i=1}^T exp(e_i)}\]For smoothint, they changed the exponential function in equation above with logisitic sigmoid function \(\),
\[\alpha_i = \frac{\sigma(e_i)}{\sum_{i=1}^T \sigma(e_i)}\]With their model and attention machanism, they carried out two sequence classification task.
-
Dialogue act(DA) detection: it is about categorizing the intention behind the speaker’s move in conversation.
-
Key term extraction: its goal is to automatically extract relevant terms from a given document.
For detailed experiment analysis, you can found in Neural Attention Models for Sequence Classification: Analysis and Application to Key Term Extraction and Dialogue Act Detection (Shen and Lee, arXiv 2016)