This is a brief summary of paper for me to study and organize it, MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (Sun et al., ACL 2020) that I read and studied.
They proposed task-agnostic BERT for Resouce-Limited Devices by using layerwise knowledge distilattion technique as follows:
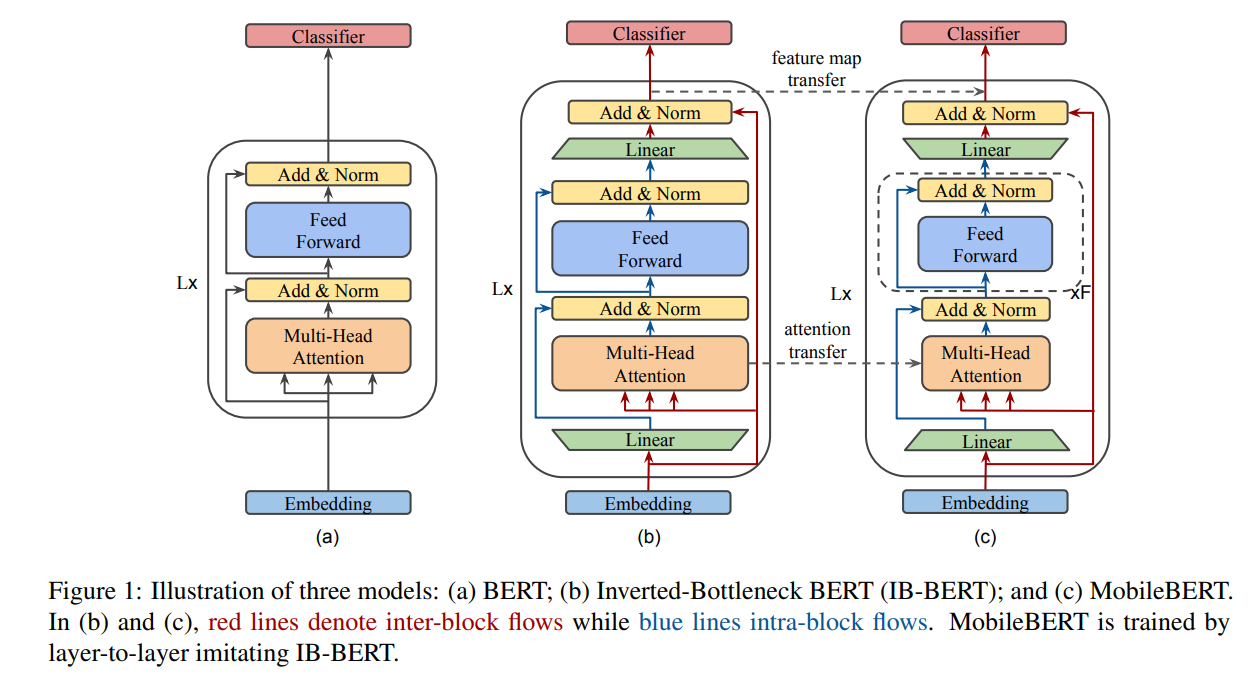
For detailed experiment analysis, you can found in MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (Sun et al., ACL 2020)
Note(Abstract):
Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot be deployed to resourcelimited mobile devices. In this paper, they propose MobileBERT for compressing and accelerating the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERTLARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks. To train MobileBERT, they first train a specially designed teacher model, an invertedbottleneck incorporated BERTLARGE model.
Download URL:
The paper: MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (Sun et al., ACL 2020)
The paper: MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (Sun et al., ACL 2020)