This is a brief summary of paper for me to study and organize it, Character-based Neural Machine Translation (Ling et al., arXiv 2015.) that I read and studied.
This paper propose a neural translation model that learns to encode and decode using character level.
In other words, they used composition model to make character embedding into word embedding in input and output layer.
First of all, they designed a attention-based neural translation model presented by Bahdanau et al.(2015) which is described as follows:
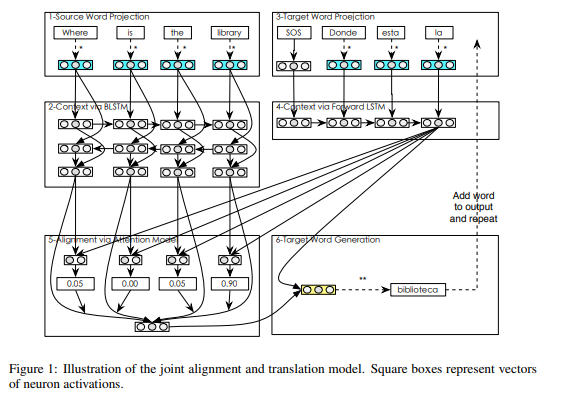
Since the attention-based neural machine translation model is word-based neural network model, it has a problem which has to bottleneck of softmax.
In order for them to resolve this problem, they adapt the word-based neural machine translation model to operate over character sequences rather than word sequence.
However, they retain the notion of words when using the character embedding in each input and output layer.
In input layer, they use bidirectional LSTM to represent character sequence into word embedding like this:
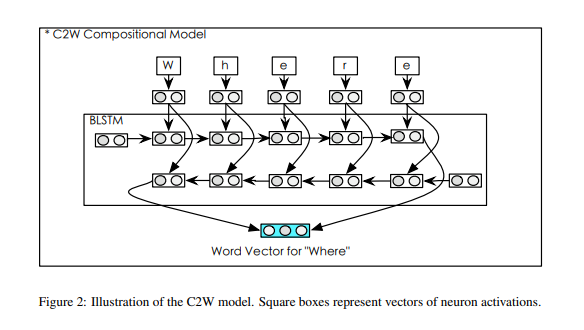
Their composition model for word vector from characters builds a representation of the words using characters, by reading character left-to-right and vice versa.
The representation of the word is obtained by combining each final state from forward LSTM and backward LSTM.
In output layer, they also use bidirectional LSTM such as the method of input layer. The figure belwo shows the generation of words from characters in output layer:
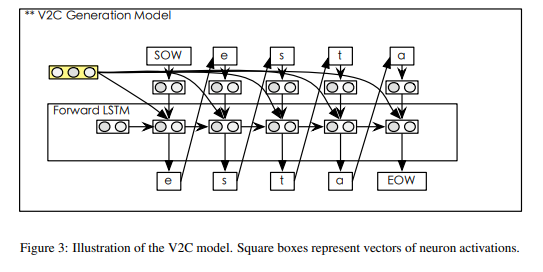
The disticntion between input and output layer is that the output use the alignment and output context.
For detailed experiment analysis, you can found in Character-based Neural Machine Translation (Ling et al., arXiv 2015)
Reference
- Paper
- How to use html for alert