This is a brief summary of paper for me to note it, Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation (Johnson et al., TACL 2017)
They use a model sharing weight between multilingual language pair.
They only amend to data which introduce artificial token at the beginning of the input sentence to specify the required target sentence.
The basic model is the following:
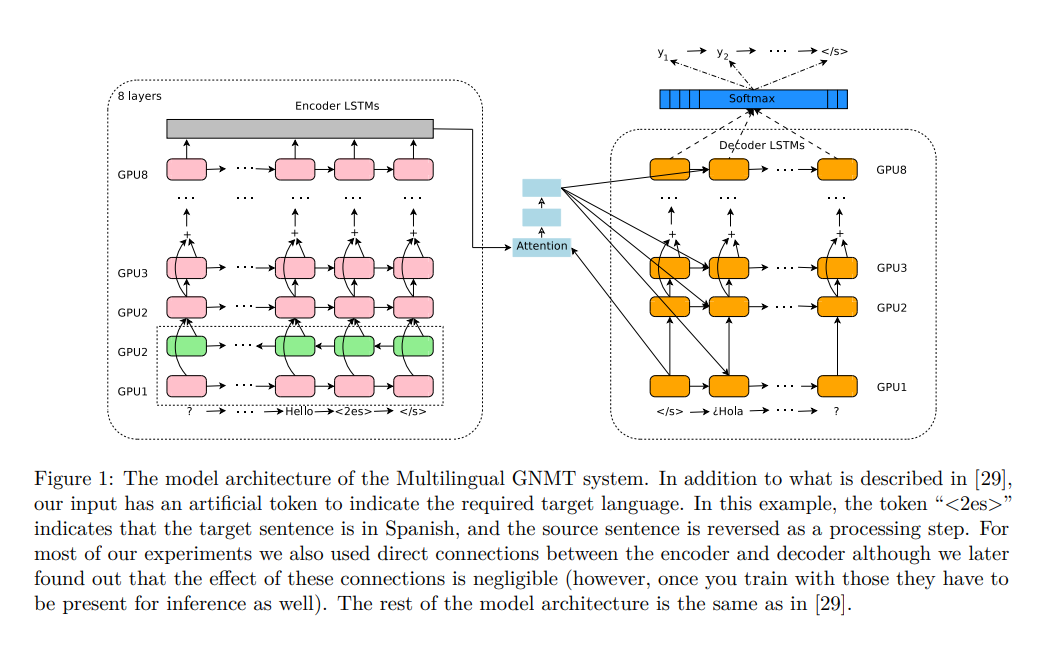
Their method’s strength is explained as follows:
- Simplicity:
Since no changes are made to the architecture of the model, scaling to more languages is trivial — any new data is simply added, possibly with over- or under-sampling such that all languages are appropriately represented, and used with a new token if the target language changes.
Since no changes are made to the training procedure, the mini-batches for training are just sampled from the overall mixed-language training data just like for the single-language case.
Since no a-priori decisions about how to allocate parameters for different languages are made the system adapts automatically to use the total number of parameters efficiently to minimize the global loss.
A multilingual model architecture of this type also simplifies production deployment significantly since it can cut down the total number of models necessary when dealing with multiple languages.
Note that at Google, They support a total of over 100 languages as source and target, so theoretically 1002 models would be necessary for the best possible translations between all pairs, if each model could only support a single language pair.
Clearly this would be problematic in a production environment.
Even when limiting to translating to/from English only, we still need over 200 models.
Finally, batching together many requests from potentially different source and target languages can significantly improve efficiency of the serving system.
In comparison, an alternative system that requires language-dependent encoders, decoders or attention modules does not have any of the above advantages.
- Low-resource language improvements:
In a multilingual NMT model, all parameters are implicitly shared by all the language pairs being modeled.
This forces the model to generalize across language boundaries during training.
It is observed that when language pairs with little available data and language pairs with abundant data are mixed into a single model, translation quality on the low resource language pair is significantly improved.
- Zero-shot translation:
A surprising benefit of modeling several language pairs in a single model is that the model can learn to translate between language pairs it has never seen in this combination during training (zero-shot translation) — a working example of transfer learning within neural translation models.
For example, a multilingual NMT model trained with Portuguese→English and English→Spanish examples can generate reasonable translations for Portuguese→Spanish although it has not seen any data for that language pair.
They show that the quality of zero-shot language pairs can easily be improved with little additional data of the language pair in question (a fact that has been previously confirmed for a related approach which is discussed in more detail in the next section).
The paper: Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation (Johnson et al., TACL 2017)
Reference
- Paper
- How to use html for alert