This is a brief summary of paper for me to study and simply arrange it, Character n-gram Embeddings to Improve RNN Language Models (Takase et al., AAAI 2019) I read and studied.
They propose character n-gram embedding with simplified Multi-dimensional self embedding as follows:
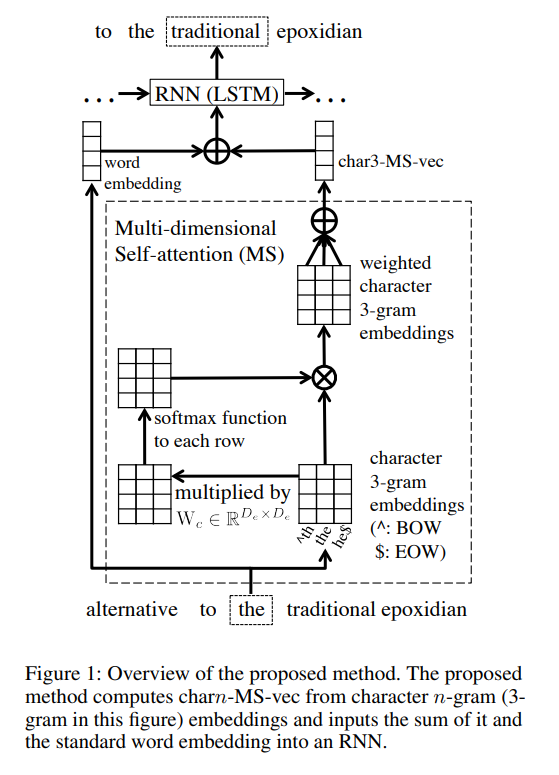
The Multi-dimensional self embedding used the Mutli-dimensional self attention.
The Multi-dimensional self attention compute weights for each dimension of given embeddings and sumps up the weighted embeddings(i.e., element-wise weighted sum).
They used anothe way to improve perplexity. it is word tyiing which shared the embedidng matrix with weigth matrix to evaluate the probablity distribution.
Aslo They showed the their model is superior on the application task such as machine translation and headline generation tasks.
The paper: Character n-gram Embeddings to Improve RNN Language Models (Takase et al., AAAI 2019)
Reference
- Paper
- How to use html for alert
- For your information