This is a brief summary of paper for me to study and arrange for Neural Domain Adaptation with Contextualized Character Embedding for Chinese Word Segmentation (Bao et al., NLPCC 2017) I read and studied.
This paper is a research ralted to chinese word segmentation task.
They adjust the dimenstion of a vector making with context character vectors in window size of 5.
For example, we have a sequence of characters in window size of 5 like \(w_1\) = \([x_{i-2}, x_{i-1}, x_{i}, x_{i+1}, x_{i+2}]\) which is concatenation of 5 character embedding around \(x_i\)
The semantic mask is generated as :
\[mask_i = \sigma(Ww_i + b)\]The contextualized embedding is generated by masking the character embedding \(x_i\) as :
\[c_i = maks_i \odot x_i\]where \(\odot\) is element-wise product
the hypothesis above assumes that:
Embedding is usually a n-dimension vector for each character. The n-dimension can be viewed as n hidden semantics dimensions. They assume that one meaning of the character may be represented by some of n hidden semantics dimensions. Accordingto this assumption, the semantic mask is generated by the contextual information to specify the meaning of each character.
In order to train teh contextualized character embedding, they use character sequence to sequence auto-encoder with LSTM.
after contextualized charater embedding by seqeunce to sequence model. They implemented word segmentor with convolutional layer as follows:
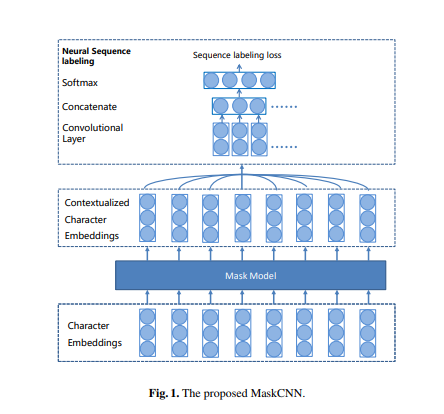
Their method shares the contextualized character embedding layer with character sequence auto encoder and the neural segmentor.
In their method, first, unlabelled data from both source and target domains are employed to train the contextualized character embedding layer and character sequence auto-encoder During this step, the characteristics of both domains are stored in the contextualized character embedding layer and the contextualized character embedding layer is learned to resolve the character ambiguous by considering surrounding characters. Then the contextualized character embedding is kept fixed to avoid domain-specific training, and the neural segmenter is trained by source domain annotated data. In this step, the segmenter is trained to do word segmentation based on the contextualized character embedding.