This is a brief summary of paper for me to study and organize it, Exploring the Limits of Language Modeling (Jozefowicz et al., arXiv 2016) that I read and studied.
Saying the language moedl,which is based on neural network, not only econdes compolexities of language such as grammatical structure, but also distill a fair amount of in ofmration about the knowledge that a corpora may contain, they fouced on neural network-based language models to explore the limits of them on the popular One Billion Word Benchmark.
For their expriments, the architectures that they considered is representede in figure below:
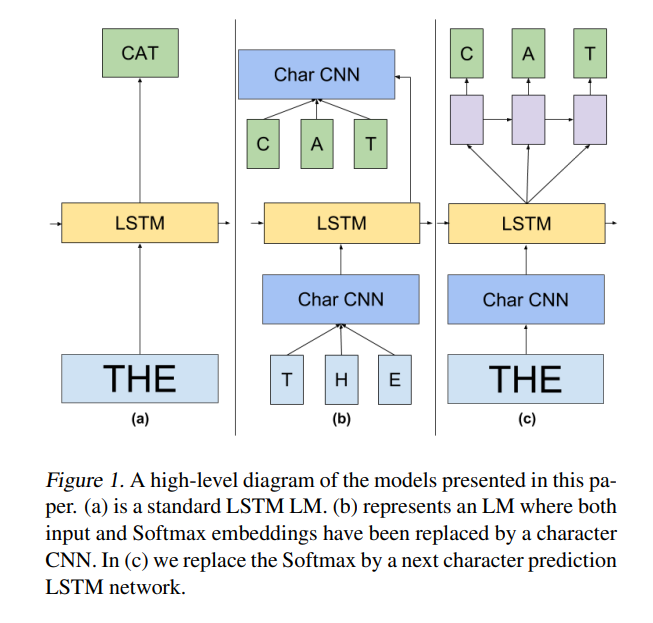
They propose a softmax over large vocabularies to go through similarity and difference between Noise Constrative Estimation(NCE) and Importance Sampling(IS).
Simply speacking, the difference between them is that IS they define considers a multiclass classification problem with a softmax and cross-entropy loss and NCE considers a binary classification task between true or noise words with a logistic loss.
For IS(i.e. useful for training but maintain awful at inference time for still computing the normalization term over all words), in particular, they always used \(w_1 \in W\) as the word from true data.
So They said the contribution of their research as follow:
- We explored, extended and tried to unify some of thecurrent research on large scale LM.
- Specifically, we designed a Softmax loss which is based on character level CNNs, is efficient to train, and is as precise as a full Softmax which has orders of magnitude more parameters.
- Our study yielded significant improvements to the state-of-the-art on a well known, large scale LM task: from 51.3 down to 30.0 perplexity for single models whilst reducing the number of parameters by a factor of 20.
- We show that an ensemble of a number of different models can bring down perplexity on this task to 23.7, a large improvement compared to current state-of-art.
- We share the model and recipes in order to help and otivate further research in this area.
On my opinion, I am with the fact that they used a large dataset on NN-based LMs at the time they experimented
For detailed experiment analysis, you can found in Exploring the Limits of Language Modeling (Jozefowicz et al., arXiv 2016)
Reference
- Paper
- How to use html for alert